

В декабре 2017 г. группа ведущих американских технологических ученых JASON опубликовала отчет «Искусственный интеллект для здоровья и здравоохранения» («Artificial Intelligence for Health and Health Care»). Это исследование было выполнено по заказу Агентства исследований и оценки качества медицинской помощи (Agency for Healthcare Research and Quality), Управления национального координатора по информационным технологиям в здравоохранении (the Office of the National Coordinator for Health IT) и Фонда Роберта Вуд-Джонсона (the Robert Wood Johnson Foundation).
JASON было поручено изучить, как искусственный интеллект может помочь в формировании будущее общественного здоровья, здравоохранения и предоставления медицинских услуг в США. Ученым JASON необходимо было сформулировать практические рекомендации для федеральных властей США и разработчиков относительно возможностей и различных важных аспектов применения искусственного интеллекта. В частности, JASON попросили сосредоточиться на технических возможностях, ограничениях и приложениях ИИ в области здоровья и здравоохранения, которые могут быть реализованы в течение следующих 10 лет.
Пресс-релиз об этой работе представлен тут https://www.healthit.gov/buzz-blog/interoperability/hype-reality-artificial-intelligence-ai-transform-health-healthcare/. Полнотекстовая версия отчета доступна по адресу https://www.healthit.gov/sites/default/files/jsr-17-task-002_aiforhealthandhealthcare12122017.pdf
JASON - независимая группа элитных ученых, которая уже более 50 лет консультирует федеральное правительство Соединенных Штатов Америки по вопросам науки и техники, в основном чувствительного характера. Изначально группа была создана в 1960 г. в качестве попытки вырастить молодое поколение ученых, большая часть исследований которых носила военный характер. В настоящее время область интересов исследователей включает информатику здравоохранения, кибервооружение и возобновляемые источники энергии.
Один из самых полных списков работ JASON доступен тут https://fas.org/irp/agency/dod/jason/
Далее представлен сжатый перевод отчета JASON, выполненный компанией К-МИС в марте 2018 г.
Важное предупреждение! Данный русский перевод не является официальным с точки зрения США. Министерство здравоохранения и социальных служб США (или любая другая организация США) не может предоставлять каких-либо официальных гарантий относительно точности перевода или быть ответственным, если есть какие-либо недоразумения из-за представленного текста.
Введение
Искусственный интеллект (ИИ) в настоящее время обсуждается почти в каждой области науки и техники. Крупные научные исследования, такие как ImageNet Large Scale Visual Recognition Challenges, предоставили доказательства, что например в распознавании изображений компьютеры могут достичь способности, подобной человеческой. ИИ привел к значительному прогрессу в распознавании речи и обработке естественного языка. Все эти успехи подняли вопросы о том, как такие возможности могут поддержать или даже улучшить процессы принятия решений в здравоохранении и предоставлении медицинских услуг.
Некоторые резонансные научные работы, опубликованные недавно, продемонстрировали, что ИИ может действительно осуществлять клиническую диагностику на основе медицинских изображений на уровне опытных врачей, по крайней мере, на конкретных примерах.
Перспектива ИИ тесно связана с наличием соответствующих данных, которые в области здравоохранения представлены в обилии. Однако, качество и доступность этих ресурсов остается значительной проблемой в США. С одной стороны, данные здравоохранения связаны с вопросами конфиденциальности, что делает сбор и обмен данных в области здравоохранения особенно затруднительным по сравнению с другими типами данных. Более того, данные здравоохранения собирать достаточно дорого, например, в случае продолжительных исследований и клинических испытаний. Отсутствие совместимости систем электронных медицинских карт (ЭМК) служит помехой даже самым простым вычислительным методам, а неспособность существующих ЭМК собрать информацию о социальных аспектах жизни человека и окружающей среде являются серьезным недостатком.
ИИ в стартапах медицинских услуг. Источник: CB Insights (2016).
В частном здравоохранении имеется широкая заинтересованность в ИИ, в сборе данных о состоянии здоровья и его применениях, что продемонстрировано многочисленными новыми компаниями, связанными с ИИ в здравоохранении и медицинском обслуживании. Большинство новых компаний имеют головной офис в США. Новые компании были созданы в 15 странах, за пределами США, с наибольшим количеством в Великобритании и Израиле.
ИИ был рядом с нами в течение десятилетий, его обещание преобразить нашу жизнь давалось часто, но при этом оставаясь во многом невыполненным. Исследовательские программы ИИ угасали и расцветали, подпитываемые расширением возможностей в вычислительных аппаратных средствах и разработкой связанных с ними алгоритмов, в также, в некоторой степени, рекламной шумихой.
Начиная примерно с 2010 года, область ИИ получила толчок в развитии благодаря широкомасштабным успехам специфической, известной десятилетия технологии многослойных нейронных сетей (NNs). Две ключевые разработки способствовали этому:
1) быстрые графические процессоры (Graphics Processor Units, GPUs), позволяющие обучать намного более крупные и более глубокие (т.е. более многослойные) сети
2) большие маркированные массивы данных (изображения, вэб-запросы, социальные сети и т.д.), которые могли быть использованы как обучающие испытательные модели.
Эта комбинация дала толчок появлению «парадигм управления данными» глубокого обучения (Deep Learning, DL) на глубоких нейронных сетях, особенно с архитектурой, названной «Сверточные Нейронные Сети» (Convolutional Neutral Networks, CNNs)».
В результате своего исследования JASON пришли к заключению, что в отличие от предыдущих эпох воодушевления по поводу ИИ, сейчас потенциал применений ИИ в здравоохранении и медицинском обслуживании может действительно изменить ситуацию, потому что американское общество подготовлено к восприятию новых подходов к здравоохранению на основе ИИ сосредоточением следующих трех главных факторов:
1) неудовлетворенность действующей системой здравоохранения
2) повсеместность сетевых и мобильных интеллектуальных устройств
3) адаптация к удобству и обслуживанию на дому
ИИ в диагностике состояния здоровья: возможности и вопросы клинической практики
В медицинской диагностике получены значимые подтверждения потенциальной полезности технологий ИИ на основе глубокого обучения. Мы рекомендуем параллельно с продолжением базового исследования этих методов, которое, скорее всего, приведет к дальнейшему продвижению вперед, сконцентрировать работу на создании строгих подходов тестирования и проверки правильности клинического использования алгоритмов ИИ. Это необходимо для завоевания доверия в медицинском сообществе и предоставления ответной реакции исследователям об областях, где наиболее необходимо непрерывное развитие.От алгоритмов ИИ, включая глубокое обучение, не должен ожидаться результат по уровню выше, чем обучающие наборы данных. Когда имеются хорошие обучающие выборки, содержащие самые высокие уровни медицинских знаний, построенные на глубоком обучении в клинических ситуациях, приложения действительно обеспечивают потенциал предоставления неизменно высококачественных результатов. Одна из амбициозных целей таких применений – сделать высококачественные медицинские услуги доступными для всех.
Одним из примером успехов ИИ в диагностике является выявление диабетической ретинопатии в изображениях на сетчатке глазного дна. Многие заболевания глаз могут быть диагностированы посредством неинвазивного изображения сетчатки через зрачок. Скрининг на ранних этапах для диабетической ретинопатии важен, так как заранее начатое лечение может предотвратить потерю зрения и слепоту у быстро увеличивающегося количества пациентов с диабетом. Такой скрининг также дает возможность выявит другие глазные болезни, а также сигнализировать о заболевании сердечно-сосудистый системы.
Оценка изображения требует квалифицированных специалистов и может быть произведена дистанционно. С появлением цифровой фотографии, цифровая запись изображений сетчатки глаза может осуществляться в рабочем порядке через системы архивации и передачи изображений (Picture Archiving and Communication Systems, PACS).
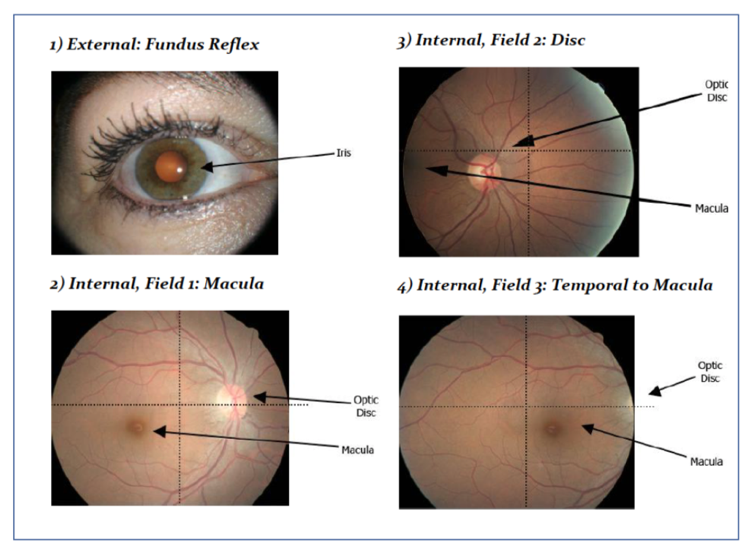
Стандартные форматы изображений для диабетической ретинопатии (правый глаз). Источник: EYEPACS LLC 2017.
Недавно было наглядно продемонстрировано трансформационное усовершенствование в автоматизированном анализе изображений на сетчатке с использование алгоритмов глубокого обучения. Алгоритм обучался на наборе данных из свыше 100 тыс. изображений. Каждое изображение в наборе данных оценивалось 3-7 офтальмологами, чтобы обеспечить обучение со значительно сниженной вариативностью. Результаты испытаний просто удивительные. При отборе на высокую специфичность (низкое ложноотрицательное), выданная чувствительность /специфичность – 90.3% / 98,1% и 87.0% / 98,5%. При отборе на высокую специфичность, выданные значения – 97.5% / 93.4% и 96.1% / 93.9%. Эти результаты выгодно отличаются от оценок в ручном режиме, даже сделанных на основании изображений множественных участков. Они также являются важным усовершенствованием предыдущих автоматизированных оценок, которые постоянно страдали от значительно более низких значений чувствительности.
Таким образом было показано, что алгоритм глубокого обучения дает большую надежду на обеспечение результатов улучшенного качества с большей доступностью. Необходимо продолжение работы для его использования в качестве одобренного клинического стандарта. Когда он получит законное признание, его использование можно предусмотреть в широком выборе сценариев, включая поддержку принятия врачебных решений в существующей практике, более быстрый и менее затратный анализ вместо оценки в ручном режиме или диагностику для населения, не получающего услуги должного качества и в должном объеме.
Представленный выше успех обусловлен доступом к большим массивам медицинских изображений, некоторые из которых были доступны в профессионально сохраняемых архивах. Каждое изображение требовало разработки маркированного набора данных для обучения. Это было достигнуто благодаря трудоемким и дорогостоящим независимым профессиональным оценкам изображений. Доступ к маркированным данным высокого качества является серьезным барьером в развитии и оценке алгоритмов ИИ для принятия клинических решений. Процесс разработки обучающих маркированных данных из существующих учетных систем требует рассмотрения электронных медицинских карт квалифицированными специалистами для создания полноценных маркировок. В результате связанных с этим затрат и времени многие доступные для широкого круга людей наборы маркированных образцов слишком ограничены для обучения и тестирования алгоритмов ИИ.
Выводы: Алгоритмы ИИ на основе обучающих наборов высокого качества продемонстрировали эффективность работы по анализу медицинских изображений на уровне врачебных возможностей, заложенных в использованных для обучения данных. От алгоритмов ИИ не может ожидаться эффективность работы на более высоком уровне, чем их обучающие данные, но они должны обеспечивать постоянство аналогичного уровня эффективности для изображений в границах обучающего диапазона.
Рекомендации: поддерживать оценку алгоритмов ИИ, используя маркированные данные на уровнях, превышающих стандартные оценки, например, использование результатов последующего этапа диагностического тестирования (использование результатов биопсии для маркировки дерматологических изображений).
В США принятие приложений ИИ для клинической практики будет регулироваться комбинацией нормативов Управления по надзору за качеством пищевых продуктов и лекарственных средств (Food and Drug Administration, FDA) и бизнес-моделями в клинической сфере. Для того, чтобы результаты работы ИИ были приняты в стандартах медицинской помощи, требуется проведение клинических исследований.
Клинические испытания и регулирование – только часть вопроса о внедрении применений ИИ. Дополнительно клинические врачи или профессионалы в сфере здравоохранения (например, инструктор по общефизической подготовке, врач или специалист в области общественного здравоохранения) должны иметь желание ввести применение ИИ в свою рабочую практику. Это принятие будет зависеть от того, как хорошо устройства mHealth и приложения вписываются в существующие системы и практики. Однако, даже для поддержки разработки клинических испытаний и уверенности, что применения ИИ не противоречат законодательству, включая нерегулируемые применения, необходимо подтверждение технической правильности алгоритмов.
Выводы: Процесс развития новых технологий как принятый стандарт услуг использует устойчивую практику научно-исследовательских и опытно-конструкторских разработок, прошедших экспертную оценку и может обеспечить защиту от использования вводящих в заблуждение или плохо проверенных алгоритмов ИИ. Использование диагностики ИИ как замены принятым этапам в медицинских стандартах предоставления услуг потребует намного большей проверки и оценки, чем использование такой диагностики для предоставления подтверждающей информации, помогающей принимать решения.
Рекомендации: поддерживать работу для подготовки многообещающих результатов применения ИИ с целью проведения тщательных процедур одобрения, необходимых для принятия в клиническую практику. Создать методику тестирования и проверки правильности для алгоритмов ИИ для оценки эффективности работы алгоритмов в условиях, отличных от обучающего набора.
Быстрое распространение устройств и приложений для сбора данных и анализа
Смартфоны и другие интеллектуальные технологии уже являются начальной платформой для обеспечения здоровья и благополучия посредством мобильных и цифровых приложений. Эти приложения и устройства поддерживают полный спектр от здоровых до больных, например, от эпизодических пользователей приложения по фитнесу (Fitbit) до диабетических больных, использующих устройства для контроля уровня глюкозы в крови.
Поднимаются вопросы в отношении использования и полезности этих устройств отдельными людьми и желанию медицинского сообщества внедрить мобильные и цифровые приложения в область здравоохранения. Проводится активное исследование по структуре и тестированию полезности приложений и устройств. Многие мобильные и цифровые приложения медицинских услуг mHealth включаются в клинические испытания. Они используются как механизм для сбора информации для испытаний, оценки конкретного устройства или использования приложения, или для оценки их пользы в комбинации с другим поведением в отношении здоровья. Например, судя по отчетам, одно только приложение Fitbit в 2016 году использовалось в 21 клиническом испытании.
Этот рост в развитии более серьезных медицинских устройств, которые могут использоваться для мониторинга и информировании профессионалов о состоянии здоровья, привлекли внимание Американской медицинской ассоциации (AMA). AMA недавно приняла ряд принципов для содействия безопасным мобильным и цифровым приложениям медицинских услуг mHealth. AMA способствует, чтобы врачи поддерживали и устанавливали взаимоотношения пациент-врач, используя приложения и связанные с ними устройства, приборы контроля и датчики.
Исследование AMA, опубликованное в 2016г. утверждает, что 31% врачей видят потенциал цифровых инструментов для улучшения обслуживания пациентов и около половины интересуются цифровыми инструментами, потому что верят, что они улучшат существующие практики в отношении эффективности, безопасности пациента, усовершенствованных диагностических возможностей и взаимоотношений пациент-врач.
Все это – многообещающие направления для развития и применения мобильных и цифровых инструментов медицинских услуг mHealth. Центр внимания здесь - типы устройств и приложений с потенциалом преимуществ от приложений ИИ или в их отдельных функциях или, когда данные, генерированные устройством, могут быть интегрированы с другой информацией о здоровье для поддержки хорошего здоровья в противовес болезни.
Ниже перечислены несколько конкретных примеров современных инструментов мониторинга здоровья, доступных для использования на мобильных устройствах.
- Персональная ЭКГ. Kardia Mobile произвела устройство записи персональной ЭКГ, одобренное Управлением по контролю качества пищевых продуктов и лекарственных средств. Платформа использует подушечку пальца и приложение смартфона для записи ЭКГ в окне пропускания волн длиной более 1.3µм х 30. Устройство работает без проводов и гелей. Платформа претендует на выявление на основе ИИ мерцательной аритмии.
- Болезнь Паркинсона. CloudUPDRS – приложение смартфона, способное оценить симптомы болезни Паркинсона. Приложение использует гироскоп, имеющийся во многих мобильных устройствах для анализа и измерения тремора, состояний при ходьбе и выполнение пальцевого теппинг-теста. Алгоритмы ИИ дифференцируют действительный тремор и «плохие данные», такие как выпавший из рук телефон или неправильное действие в ответ на вопрос приложения. Этот инструмент позволяет пациентам с болезнью Паркинсона проводить тестирование на дому, обеспечивая ценные и количественные результаты о том, как факторы их личного образа жизни и медицинское лечение могут воздействовать на их симптомы.
- Отслеживание и контроль астмы. AstmaMD предлагает ручной расходомер, измеряющий работу легких, оценивающий пиковый расход во время выдоха. Расходомер совмещен с приложением, регистрирующим данные для людей с астмой и другими болезнями органов дыхания. Пользователи также могут записать симптомы и лекарственные средства. Интересная особенность этого приложения: пользователи могут пользоваться программой, в которой их данные анонимно загружаются в базу данных Google, собираемую для исследовательских целей. AstmaMD заявляет, что «анонимные, совокупные данные помогут установить взаимосвязь между астмой и факторами окружающей среды, инициирующими факторами и изменением климата».
Технологии такого рода могут собрать информацию очевидной и жизненной важности для пациентов, но мы вновь должны обратить внимание, что каждый новый поток данных должен быть оценен, собран и организован для форматов, согласующихся с клиническими потребностями и приложениями ИИ.
Мобильные устройства и приложения могли бы стать богатым источником данных для максимального использования крупномасштабных приложений ИИ. Это уже происходит. Но предстоит сделать многое для оптимизации быстрого развития приложений мобильных врачебных услуг, устройств и датчиков. Значительных шагов вперед в создании инфраструктуры хранения и обработки данных от этих устройств не сделано, вероятно, из-за того, что проблема просто очень широка. Одна из областей внимания должна быть направлена на сбор данных и инфраструктуру для поддержки приложений ИИ, улучшающих эффективность и принятие инструментов мобильных врачебных услуг и таким образом дающих людям больше самостоятельности в отношении здоровья. Более того, обеспечение доступа к данным, собранным благодаря приложениям мобильных врачебных услуг и устройств, могло бы способствовать лучшему представлению исследователей об здоровье населения посредством применения ИИ.
Быстрое развитие и принятие приложений ИИ в здравоохранении в дистанционном доступе заняло прочное место и вне США. Один такой пример – глубокое обучение от компании DeepMind Technologies. В 2016г. DeepMind запустила несколько инициатив в сфере здравоохранения под руководством своего подразделения DeepMind Health.
DeepMind работает с Фондом больничного траста (Hospital Trust Foundation) национальной системы здравоохранения Великобритании с целью разработки приложений ИИ, использующих электронные медицинские карты пациентов из множества больниц Лондона. О быстром темпе развития этих приложений ИИ в здравоохранении свидетельствует то, что наиболее ценная информация о планах подразделения DeepMind Health поступает из исследовательских новостных статей, написанных в течение нескольких последних месяцев этого исследования. Оно сфокусировано на вопросах прозрачности, конфиденциальности и этики, связанных с предоставлением продуктов ИИ в здравоохранении. Данные пациентов национальной системы здравоохранения Великобритании были предоставлены Google без информированного согласия пациентов. Некоторые спорят, что это нарушает законодательство Великобритании, заявляя, что «данные о пациенте без прямого согласия могут быть использованы только для предоставления непосредственных медицинских услуг». Тем не менее, эта полемика не затормозила постоянное и расширяющееся сотрудничество DeepMind с национальной системой здравоохранения Великобритании.
Выводы: Революционные изменения в здравоохранении и оказании медицинских услуг уже начались в использовании интеллектуальных устройств для мониторинга личного здоровья. Многие из этих проявлений происходят за рамками традиционного диагностического и клинического окружения. В будущем ИИ и интеллектуальные устройства станут все более взаимозависимыми, включая сферы, затрагивающие здоровье. С одной стороны, ИИ будет использоваться для подпитки связанных со здоровьем мобильных устройств и приложений. С другой стороны, мобильные устройства создадут огромные массивы данных, которые смогут открыть новые возможности в развитии инструментов на основе ИИ в области здравоохранения и оказания медицинских услуг.
Рекомендации: Поддерживать развитие приложений ИИ, которые могут повысить эффективность работы новых мобильных устройств и приложений для мониторинга. Разработать инфраструктуру данных для сбора и объединения данных, полученных от интеллектуальных устройств для поддержки приложений ИИ. Отслеживать развитие в зарубежных системах медицинских помощи, обращая внимание на полезные технологии, а также неудачи в технологии.
На неизбежном приходе Интернет в диагностику и медицинские услуги будут заработаны огромные деньги, что будет способствовать появлению в данной сфере разного рода компаний и заслуживающих внимания, и не заслуживающих. Например, уже есть много платных онлайн услуг, которые помогут людям понять их данные о совокупности хромосомных наследственных факторов или предложат отчеты о состоянии здоровья. Как американцам узнать, на какие из этих источников можно положиться?
Рассмотрим пример с выявлением рака кожи. Компьютеризированное автоматизированное выявление рака кожи было продемонстрировано на клинических изображениях, подтвержденных биопсией и проверено 21 дерматологом. Параллельно уже существуют онлайн услуги для дистанционной дерматологической диагностики представленных онлайн изображений родинок на коже. Мы можем представить себе мошенническую услугу, с просьбой предоставления сделанных самими людьми изображений с оплатой за автоматизированный «шарлатанский» диагноз в ответ, диагноз, для которого не использовались какие-либо проверенные классификационные схемы. Вероятнее всего, методы, используемые любой компанией, могут быть скрыты или завуалированы, чтобы пользователь никоим образом не мог оценить ее надежность. Например, новая компания Skinvision, основанная в Нидерландах для «выявления раковой меланомы кожи», выпустило приложение, с помощью которое пациенты делают фото и получают от программы анализ, диагноз и сервисы контроля. Предоставлено очень мало информации об использующихся методах, кроме того, что Skinvision использует «математическую теорию «фрактальной геометрии» для диагностики потенциальной меланомы на основе медицинских изображений» и что «был разработан и протестирован совместно с дерматологами алгоритм и проверки на отклонения в цвете, текстуре и форме очага изменения», хотя в другом месте мелким шрифтом на интернет-сайте указано, что «наше решение не является средством диагностирования».
Вывод: существует возможность увеличения ложной информации, которая может навредить или воспрепятствовать принятию приложений ИИ для сферы здравоохранения. Уже появились интернет-сайты, приложения и компании, надежность которых, по имеющейся информации сомнительна.
Рекомендация: для предотвращения увеличения объема ложной информации в этой растущей сфере, необходимо поддерживать участие научных обществ для содействия и одобрения лучших практик и внедрения приложений ИИ в здравоохранение.
Разработка развитых алгоритмов ИИ
Вопросу наличия высококачественных исходных данных для машинного обучения должно быть уделено значительное внимание, если рассматривается задача реализовывать потенциал ИИ в сфере здравоохранения. Есть много аспектов, которые необходимо учесть. Прежде всего, это цена создания маркированных данных высокого качества – это может потребовать найма квалифицированных специалистов по анализу изображений или обеспечения дополнительных проверок (таких как биопсии) для создания маркеров. В больших объемах, необходимых для наборов данных ИИ, это может быть дорогостоящим. Другие аспекты включают тот факт, что данные могут содержать информацию о реальных людях, требующую особо деликатного обращения. Более того, в биологии и в медико-биологических науках принято тщательно защищать чьи-либо личные данные, которые были, как правило, дорогие, и для сбора которых потребовалось значительное время.
Выводы: Наличие и доступ к высококачественным данным являются решающими факторами развития окончательной реализации приложений ИИ. Существование некоторых из таких данных уже подтвердило свою ценность в предоставлении возможностей для развития приложений ИИ в медицинских изображениях. Достойные цели для инструментов ИИ включают ускорение открытия взаимозависимости новых видов заболеваний и оказание помощи людям в определении лучшего лечения на основе их конкретного состояния здоровья, жизненного опыта и генетических особенностей. Определение и интеграция наборов данных, необходимых для развития таких инструментов ИИ является главной задачей.
Рекомендации: Поддерживать развитие и доступ к исследовательским базам маркированных и немаркированных данных для развития приложений ИИ в здравоохранении. Поддерживать процесс выяснения, как стимулировать обмен данными и новые подходы к праву владения данными. Поддерживать оценку алгоритмов ИИ, используя данные, маркированные на уровнях, превышающих стандартную оценку, например, использование результатов от следующего этапа диагностики (использование результатов биопсии для маркировки дерматологических изображений). Поддерживать выяснение характеристики компромиссов между качеством данных, информационным содержанием (сложность и разнообразие) и размером образца с целью способствования количественному предсказанию объема и качества данных, необходимых для поддержки конкретного приложения ИИ. Определить и разработать стратегии для заполнения важных пробелов данных для здравоохранения.
Краудсорсинг
Краудсорсинг становится все более успешным для ИИ в развитии алгоритмов в сфере здоровья посредством онлайновых конкурсов. Конкуры краудсорсинга способны привлечь ведущих ученых – экспертов по данным и программистов, не являющихся узкими специалистами системы медицинских услуг. Некоторые конкурсы насчитывали тысячи участников, другие были намеренно ограничены до избранной группы десятка приглашенных участников, отобранных из круга ранее успешных конкурсантов. Длительность конкурса может быть от нескольких дней до месяцев. Денежные призы часто выдаются главным победителям, обычно в пределах от наименьшей общей суммы 10 тыс. дол. США до 100 тыс. дол. США и даже до 1 млн. дол. США. Таблицы лидеров мотивируют конкурсантов и дискуссионные клубы способствовать обмену информации, что иногда приводит к сотрудничеству в самих конкурсах. Полученный результат обычно становится общественным и служит как исходный критерий и как средство развития данной сферы.
Краудсорсинг мотивирован тем фактом, что в то время, как существует множество разнообразных стратегий, которые могут быть приложены к любой предсказуемой задаче моделирования, невозможно знать на начальном этапе, какая приемы будут наиболее эффективны.
Основная задача усилий краудсорсинга – это привлечение внимания профсообщества к крупным, хорошо-маркированным базам данных общего или частично общего пользования. Никто не мог предсказать плюсы от тщательного создания баз данных ImageNet, и мы предполагаем, что более широкое создание подобных высококачественных баз данных для здравоохранения может также дать непредвиденные плюсы. Более того, конкурсы могут помочь ускорению разработки новых алгоритмов ИИ и пониманию погрешностей и ошибок, скрытых в данных здравоохранения. Уже есть интернет-сайты, отлично подходящие для организации таких конкурсов, такие как Kaggle.
Вторая основная задача онлайновых конкурсов – как продвинуть программное обеспечение, полученное в результате конкурса к клиническим инструментам. Например, The Booz Allen Hamilton Data Science Bowl приглашает участников разработать клинически готовое программное обеспечение на основе моделей ИИ, которое может быть использовано для распознания ранних стадий рака легких.
Третья важная задача таких конкурсов – конкурсы на сегодняшний день в основном ограничены распознаванием изображений/машинным распознаванием образов. Сложные и неоднородные наборы данных, искаженные медицинские базы данных пока остаются без внимания. Хотя, напротив, крупные проекты по сбору данных (такие как исследовательская программа All of Us) будут собирать большое количество неизвестных данных и разного качества. Сопоставление данных, объединение множества разнородных источников данных – пример предложения нового типа конкурсов. Данные здравоохранения имеют особенности, отличающие их от других типов данных; конкурсы могут быть организованы так, чтобы способствовать пониманию этих отличительных черт и соответственно подстраиваться под них. Один из примеров: предоставить участникам доступ и к электронным медицинским записям, и к данным выставленных счетов с целью сбора пациентов, для которых потребуются креативные стратегии увязывания данных для разработки согласованных данных и соответствующего анализа.
Вывод: Конкурсы ИИ уже продемонстрировали свою ценность в 1) стимулировании создания большого объема данных для широкого использования 2) показе возможностей ИИ в здравоохранении, при предоставлении данных, приведенных в хорошо маркированный (а именно, с высоким информационным содержанием) формат.
Рекомендация: использовать по максимуму деятельность «краудсорсинг», активизировавшую эту сегодняшнюю революцию в ИИ. Поддерживать конкурсы, созданные для улучшения нашего понимания природы данных в области здравоохранения и медицинских услуг. Обмениваться данными на общественных форумах для привлечения ученых к оказанию помощи по поиску новых открытий, которые принесут пользу здоровью.
Глубокое обучение на основе немаркированных данных
Наиболее интуитивный процесс обучения для глубокого обучения включает маркированные данные. Однако, известны различные техники для применения глубокого обучения в контекстах, где маркированные данные недоступны или негодны. Заслуживают упоминания три из них: обучение с подкреплением, автокодировщики и генеративные состязательные сети. Каждый из них в некотором смысле создает обучающий набор.
Использованию методов ИИ для немаркированных данных в приложениях в области здоровья обращалось до настоящего времени мало внимания.
Вывод: методики для обучения на основе немаркированных данных могут быть полезными для решения вопросов с использованием данных от разнообразных наборов источников.
Рекомендации: разработать автоматизированные методы организации для широкомасштабных совокупностей данных, чтобы форматировать их для инструментов ИИ, например, как с хорошо маркированными изображениями.
Крупномасштабные медицинские данные
Амбициозная цель для здравоохранения и медицинской помощи – накопление больших массивов данных (маркированных и немаркированных) и систематически организованных медицинских данных для того, чтобы можно было определить взаимосвязи новых видов заболеваний и для подбора наилучшего лечения для людей на основе их конкретного состояния здоровья, жизненного опыта и генетических особенностей. ИИ сдерживает обещание объединить все эти источники данных с целью достижения прорыва в медицинской сфере и новых прозрений в вопросах личного и общественного здоровья. Однако, главными ограничивающими факторами будут наличие и доступность данных высокого качества, способность алгоритмов ИИ эффективно функционировать и надежность информационных потоков.
По существующим оценкам причинами 60% преждевременных смертей являются социальные обстоятельства, воздействие факторов окружающей среды и стереотипы поведения. Эти три сферы – комбинация опыта нашей жизни, основанная на том, где мы родились, живем, учимся, работаем и действуем. Часто складываются детерминанты здоровья, включающие экономическую стабильность, окружение, физическую среду, образование, питание, сообщество и социальное окружение и систему здравоохранения. К ним должна быть добавлена генетическая информация. Однако, необходимо признать, что генетическая последовательность (genetic sequencing) по-прежнему не оправдывает ожиданий объяснения многих состояний здоровья. В некоторых случаях болезни человека легко соотнести с мутациями в очень специфических генах. Но это, похоже, исключение, а не правило. Иногда болезни человека – результат комбинации генетических мутаций, и в этих случаях намного труднее отыскать генетические негативные предпосылки болезни. Более того, существует такое понятие, как случай, и восприимчивость может быть изменена поведением (например, физическими нагрузками, диетой, курением и т.п.) и воздействием внешних факторов (например, токсины окружающей среды, шумовое загрязнение окружающей среды, промышленные химикаты).
Для получения полной картины состояния здоровья, необходимо объединение данных генетики, предоставления медицинских услуг и результатов, социальных факторов, оказывающих влияние на здоровье человека. Это может включать, например, данные о физических нагрузках, привычках, диете, предоставление и обмен информацией о семейном анамнезе, пройденном лечении и социальных последствиях, связанных с хронической болезнью, широкомасштабный сбор информации о состоянии здоровья от носимых устройств и приложений на основе платформы для смарт-технологий.
Одна из главных инициатив, только начинающаяся воплощаться в США – сбор огромного количества индивидуальных данных о здоровье, включая социально-поведенческую информацию. Эта инициатива получила название «Исследовательская программа All of Us» (All of Us Research Program). Это десятилетний проект Национального института здравоохранения (National Institute of Health, NIH). Цель – найти 1 000 000 человек плюс группу лиц по всей стране, желающих поделиться своими биологическими данными, информацией об образе жизни и окружении для исследовательских целей.
Первичными данными, собранными об участниках, согласных на исследование, будут:
1) базовая информация об анамнезе и образе жизни (например, личные привычки и общее состояние здоровья),
2) измерения физических параметров (например, кровяное давление, пульс, рост, вес, обхват бедер и талии),
3) оценка биопроб (проба крови и мочи) и в некоторых случаях, тест ДНК с дополнительным согласием участника,
4) данные электронной медкарты, охватывающие большинство областей общих клинических баз данных (например, демографические данные, посещения врача, диагнозы, медицинские процедуры, лекарственные средства, лабораторные исследования и основные физиологические показатели).
Данные электронных медкарт будут собираться непрерывно на протяжении 10 лет хода исследования, означая, что участники, привлеченные к проекту сейчас, будут иметь данные, связанные с ними за 10 лет. Будущие цели – включение всех частей электронных медицинских архивов и данных от беспроводных сенсорных технологий (в том числе от мобильных/носимых устройств), а также геопространственных данных и данных об окружающей среде.
Принятием Закона «О лечении 21 века» Конгресс США выделил 1.5 млрд.$ финансирования на 10 лет для этой инициативы.
Вывод: развитие применения ИИ требует данных для обучения и пойдет плохо, если не будет значительных потоков данных. В то время как ДНК – программа для жизни, на общее состояние здоровья сильно влияют воздействия окружающей среды и социальное поведение. Существует дисбаланс в попытке сбора разнообразных данных, необходимых для применения методов ИИ к персонализированной медицине, в особенности это касается информации о токсикологии окружающей среды и ее воздействиях. Существуют методики для установления индивидуальных воздействий окружающей среды, например, скрининг токсинов крови, вопросники о питании. Существуют методики для контроля патогенного фактора окружающей среды. Существуют методики, которые могут измерить воздействий окружающей среды географически и создать системы наблюдения за окружающей средой.
Рекомендации: поддерживать активный и продуктивный сбор данных о воздействиях окружающей среды. Внести скрининг токсинов (например, диоксин, свинец) в обычный клинический анализ крови, а вопросы о питании и токсинах окружающей среды – в листы опросов о здоровье. Начать программы городского измерительного контроля и наблюдения, соответствующие географическим областям для исследовательской программы All of Us и подобных проектов в будущем. Поддерживать развитие носимых устройств для измерения токсинов окружающей среды. Поддерживать развитие широкомасштабного контроля патогенного фактора в городской и загородной среде. Разработать протоколы и IT- средства для сбора и интеграции многообразных данных.
Вопросы успеха
Если применения ИИ должны пойти дальше поддержки специализированной диагностики и обеспечить в значительной мере более широкую деятельность системы здравоохранения и медицинских услуг, необходимо обратится к решению важных вопросов. Основной из них – существующее подразумеваемое допущение, что возможности ИИ автоматически решат проблемы крупных, сложных и несовершенных данных здравоохранения.
Перспектива ИИ тесно связана с доступностью соответствующих данных. В доменах здравоохранения имеется изобилие данных. Электронные медицинские записи (Electronic health records, EHRs) – часть из них. Был отмечен рост во внедрении «базовых электронных медицинских записей» (демография, список проблем, медицинские назначения, заключения при выписке из больниц, результаты лабораторных анализов, радиологических, диагностических тестов), но только 40% больниц имеют подробные электронные медицинские записи, включающие комментарии врачей, полные лабораторные исследования и отчеты, методические рекомендации принятия решений о клинической практике и взаимодействию лекарственных средств. Более того, остается неясным вопрос стыкуемости систем электронного учета здоровья и ситуаций медицинского помощи.
Полезность данных электронных медицинских записей может быть сомнительной, помимо вопросов полноты или совместимости, потому что они не собирались для целей или под контролем использования для научных исследований. Это поднимает проблему действительного качества данных в электронных медицинских записях. Если эти данные должны использоваться для поддержки приложений ИИ, будет важно обеспечивать их качество, и контролировать, как алгоритмы ИИ будут реагировать на вопросы качества. На сегодняшний день, этот аспект был очень мало исследован.
Вывод: необходима чрезвычайная осторожность в использовании электронных медицинских записей в качестве обучающих наборов для ИИ, где выходные результаты могут быть бесполезными или вводящими в заблуждение, если обучающие наборы содержат неверную информацию или информацию с неожиданными внутренними корреляциями.
Клинические испытания, регулирование и принятие медицинскими специалистами – это только часть истории по внедрению приложений ИИ. Тем не менее, даже для поддержки развития клинических испытаний и обеспечения регламентирования приложений ИИ, даже не контролируемых приложений, необходимо подтверждение технической правильности алгоритмов. В то время как алгоритмы ИИ, такие как глубокое обучение, могут давать удивительные результаты, необходима работа для повышения уверенности, что они могут работать, как требуется, в ситуациях, когда имеется риск здоровью и жизни. Это – вне зависимости от надежды на какие-то непрерывные улучшения, уже произошедшие в распознавании изображений или различных аспектах обработки естественного языка. Задачи здесь более прагматичны.
Выводы: методы для обеспечения прозрачности через раскрытие крупномасштабных вычислительных моделей и методов в контексте научной воспроизводимости только начинают развиваться в научном сообществе.
Рекомендации: поддерживать развитие крайне необходимых средств обеспечения защиты, которые очень важны для обеспечения принятия ИИ для общественного здоровья, здравоохранения и предоставления медицинских услуг. Способствовать развитию и принятию прозрачных процессов и политики с целью обеспечения воспроизводимости для крупномасштабных вычислительных моделей. Предотвращать рост неверной информации в этой развивающейся области, поддерживать привлечение научных обществ для поощрения и внедрения лучших практик развития приложений ИИ в здравоохранении.
Послесловие
Отчет завершается некоторыми размышлениями о человеческом восприятии в противовес цифровым данным во временных рамках будущего, оставшегося вне этого отчета. Одно из главных препятствий, которое предстоит преодолеть, состоит в том, чтобы информация сферы здравоохранения и медицинских услуг стала полезной. Необходимо сократить разрыв между процессом человеческого познания и цифровыми данными. Информация об отдельно взятом пациенте в большинстве случаев получается в формах, созданных так, чтобы быть доступной для медицинского персонала. Типичные данные могут включать рентгеновские снимки или МРТ, или ультразвуковые сонограммы пациента, визуальные записи функции сердца или легких в разные периоды времени или словесные описания пациента, как видит медсестра или врач. С другой стороны, когда данные хранятся в информационных системах и используются в медицинском исследовании или для разработки рекомендаций лечения, они часто сводятся к статистической информации, являющейся преимущественно цифровой. Преобразование аналоговых данных ввода в цифровые данные вывода – тяжелая задача, могущая привести к потере важной информации, которая была бы полезной для пользователя.
Когда мы думаем о конструктивном исполнении будущих информационных систем медицинской помощи, которые могли бы быть более удобными и для поставщиков информации, и для пользователей, возникает необходимость ответа на два вопроса. Один из них касается компьютерной науки, а другой – фундаментальной биологии. Вопрос компьютерной науки: может ли быть создана полная медицинская база данных в формате, доступной человеческому познанию, без утомительного и затратного перевода аналоговых данных в цифровые?
Вопрос фундаментальной биологии: является ли естественное кодирование информации в человеческом мозге собственно аналоговым, а не цифровым? Мы не претендуем, что знаем ответы на эти вопросы, но мы склонны полагать, что ответы на оба эти вопроса утвердительные.
Этот отчет JASON касается практических проблем руководства информацией сферы здравоохранения и медицинских услуг со среднесрочной перспективой, направленной только примерно на 30 лет вперед. Маловероятно, что за этот короткий период в 30 лет может произойти такой фундаментальный переход нашей вычислительной техники из цифровой в аналоговую. Но если мы посмотрим дальше на пятьдесят или 100 лет в будущее, такой фундаментальный переход становится возможным и даже вероятным. Создавая планы на близлежащее будущее, мудрым было бы не забывать о более смелых возможностях, которые, очевидно, принесут в будущем новые открытия в биологии и неврологии. Одна возможность для серьезной работы – полная замена баз данных с цифровых на аналоговые данные для более удобного обращения с ними как квалифицированных пользователей, так и неопытных новичков.