

 Статья написана в соавторстве с С.Л. Добриднюком, директором по исследованиям и инновациям, компания "Диасофт Системы". Ссылка для цитирования публикации: Гусев А.В., Добриднюк С.Л. Искусственный интеллект в медицине и здравоохранении // Информационное общество, 2017.-№4-5-С. 78-93
Статья написана в соавторстве с С.Л. Добриднюком, директором по исследованиям и инновациям, компания "Диасофт Системы". Ссылка для цитирования публикации: Гусев А.В., Добриднюк С.Л. Искусственный интеллект в медицине и здравоохранении // Информационное общество, 2017.-№4-5-С. 78-93
Введение
На сегодняшний день искусственный интеллект (ИИ) считается одним из самых перспективных направлений развития не только ИТ-отрасли, но и многих других сфер деятельности человека. В частности, решения на базе ИИ являются одной из основных надежд в плане реализации концепции «Цифровой экономики».
Как электричество изменило и привело к новой промышленной революции в XIX веке, так и искусственный интеллект становится одним из основных драйверов глубокой трансформации общества и экономики в XXI веке. Однако, в отличие от прежних промышленных революций, основной движитель этих тектонических изменений – не технологии, и не ИТ. Изменяется само общество, его уклад. Информатизация преобразует поведение потребителей. Они, имеющие доступ к разного качества информации, становятся более искушенными и требовательными. Применяя ИТ, менеджмент получил качественные профессиональные инструменты наблюдения, управления и контроля. Меняется политика государства и инвесторов, они больше не хотят вкладываться в профессии и деятельность, где есть унаследованная от прежних лет рутина, применяется низкоквалифицированный ручной труд. Идет решительная замена их роботами и сервисами на базе искусственного интеллекта.
Согласно данным IDC, объём рынка когнитивных систем и технологий ИИ в 2016 году в денежном выражении составил приблизительно 7,9 млрд. долл. Аналитики полагают, что до конца текущего десятилетия среднегодовой темп роста (CAGR) окажется на уровне 54%. В результате, в 2020 г. объём отрасли превысит 46 млрд. долл. Наибольшую долю этого рынка составят когнитивные приложения, которые автоматически изучают данные и составляют различные оценки, рекомендации или прогнозы. Инвестиции в программные платформы ИИ, которые предоставляют инструменты, технологии и сервисы на основе структурированной и неструктурированной информации, будут измеряться 2,5 млрд. долл. в год. Рынок искусственного интеллекта в области здравоохранения и наук о жизни, по оценкам Frost & Sullivan, также будет расти на 40% в год, достигнув в 2021 г. уровня 6,6 млрд. долл..
Немного истории
Искусственный интеллект имеет длинную историю, основанную на теоретических работах Тьюринга по кибернетике, датированных началом XX века. Хотя концептуальные предпосылки появились еще ранее, с философских работ Рене Декарта «Рассуждение о методе» (1637) и работы Томаса Гоббса «Человеческая природа» (1640).
В 1830-х годах английский математик Чарльз Бэббидж придумал концепцию сложного цифрового калькулятора — аналитической машины, которая, как утверждал разработчик, могла рассчитывать ходы для игры в шахматы. А уже в 1914 году директор одного из испанских технических институтов Леонардо Торрес Кеведо изготовил электромеханическое устройство, способное разыгрывать простейшие шахматные эндшпили почти так же хорошо, как и человек.
С середины 30-х годов прошлого столетия, с момента публикации работ Тьюринга, в которых обсуждались проблемы создания устройств, способных самостоятельно решать различные сложные задачи, к проблеме искусственного интеллекта в мировом научном сообществе стали относиться внимательно. Тьюринг предложил считать интеллектуальной такую машину, которую испытатель в процессе общения с ней не сможет отличить от человека. Тогда же появилась концепция Baby Machine, предполагающая обучение искусственного разума на манер маленького ребенка, а не создание сразу «умного взрослого» робота — прообраз того, что сейчас мы называем машинным обучением.
В 1954 году американский исследователь Ньюэлл решил написать программу для игры в шахматы. К работе были привлечены аналитики корпорации RAND Corporation. В качестве теоретической основы программы был использован метод, предложенный основателем теории информации Шенноном, а его точная формализация была выполнена Тьюрингом.

Математик Джон Маккарти в Лаборатории искусственного интеллекта в Стэнфорде
Летом 1956 года в Университете Дартмута в США прошла первая рабочая конференция с участием таких ученых, как Маккарти, Минский, Шеннон, Тьюринг и другие, которые впоследствии были названы основателями сферы искусственного разума. В течение 6 недель ученые обсуждали возможности реализации проектов в сфере искусственного интеллекта. Именно тогда и появился сам термин Artificial Intelligence (AI) — искусственный интеллект. Подробнее об этом событии, ставшем отправной точкой ИИ, рассказано тут https://meduza.io/feature/2017/07/01/pomogat-lyudyam-ili-zamenyat-ih-kak-v-amerike-1950-h-sozdavali-iskusstvennyy-intellekt
Следует уточнить, что исследовательские работы по ИИ не всегда шли путем победителя, а их авторы добивались успеха. После взрывного интереса инвесторов, технологов, ученых в 50-е годы XX века и фантастических ожиданий, что вот-вот компьютер заменит человеческий мозг, в 60-70-е годы наступило тяжелое разочарование. Возможности компьютеров того времени не позволяли проводить сложные вычисления. В тупик зашла и научная мысль по разработке математического аппарата ИИ. Отголоски этого пессимизма встречаются во многих учебниках по прикладной информатике, выпускаемых до настоящего времени. В общественной культуре и даже государственных нормативных документах сформировался образ робота или кибернетического алгоритма как жалкого, недостойного внимания, агента. Который может выполнять свои функции только под контролем человека.
Однако, с середины 90-х гг. интерес к ИИ вернулся, и технологии стали развиваться быстрыми темпами. С этого времени наблюдается настоящий взрыв исследований и патентной работы по этой тематике.
Развитие в наши дни
Первые примеры воодушевляющих и впечатляющих результатов применения наработок в области искусственного интеллекта удалось достичь в деятельности, требующей учета большого числа часто изменяющихся факторов и гибкой адаптивной реакции человека, например, в развлечениях и играх.
Интерес к способностям создать "умную машину", сравнимую по ее интеллектуальным возможносям с человеком, стал последовательно нарастать с 1997 года, когда суперкомпьюетр IBM Deep Blue победил действующего чемпиона мира по шахматам Гарри Каспарова. Подробнее об этом событии тут http://mashable.com/2016/02/10/kasparov-deep-blue/

Суперкомпьютер Deep Blue победил чемпиона мира по шахматам Гарри Каспарова
В 2005-2008 годах в работах по ИИ произошел качественный скачок. Математический научный мир нашел новые теории и модели обучения многослойных нейронных сетей, ставших фундаментом развития теории глубокого машинного обучения. А ИТ-отрасль стала выпускать высокопроизводительные, и, что главное, недорогие и доступные вычислительные системы. Итогом совместных усилий математиков и инженеров стало достижение за последние 10 лет выдающихся успехов, а практические результаты в проектах ИИ посыпались, как из «рога изобилия».
В 2011 году когнитивная самообучающаяся система IBM Watson победила бессменных чемпионов в игре Jeopardy! (российский аналог программы «Своя игра»).
В начале 2016 г. программа AlphaGo от Google обыграла в игру Го Фаня Хуэя, чемпиона Европы. Еще через два месяца AlphaGo со счётом 4:1 разгромила Ли Седоля, одного из лучших игроков Go в мире. Этим событием ИИ взял один из исторических рубежей — до этого считалось, что компьютеру не обыграть игрока такого уровня: слишком велик уровень абстракции и слишком много сценариев развития событий для перебора. В некоем смысле, компьютеру в игре Go надо уметь творчески «думать».
В январе 2017 г. программа Libratus, разработанная в Университете Карнеги — Меллона победила в 20-дневном покерном турнире «Brains Vs. Artificial Intelligence: Upping the Ante», выиграв на сумму более 1,7 млн. долл. Следующая победа была одержана улучшенной версией ИИ под названием Lengpudashi, против выступал участник Мировой серии покера (WSOP) Алан Дю, а также ряд ученых и инженеров. Причем особенность этой ситуации состояла в том, что игрок планировал одержать победу над ИИ, используя его слабые стороны. Тем не менее, стратегия не сработала, и продвинутая версия Libratus вновь одержала победу. Как сообщает Blomberg, один из разработчиков Libratus Ноам Браун сказал, что человек недооценивает искусственный интеллект: «Люди думают, что блеф характерен для людей, но это не так. Компьютер может понять, что если блефуешь, то выигрыш может быть больше».
За последние несколько лет решения на базе ИИ удалось внедрить во многих сферах деятельности, добившись повышения эффективности процессов, и не только в сфере развлечений. Технологические гиганты Facebook, Google, Amazon, Apple, Microsoft, Baidu и ряд других компаний вкладывают в исследования ИИ гигантские средства и уже сейчас применяют различные разработки в своей практической деятельности. В мае 2017 г. компания Microsoft выступила с заявлением, что планирует применять механизмы ИИ в каждом своем программном продукте и сделать их доступными для каждого разработчика.
Снижение стоимости ИИ платформ и повышение их доступности позволило работать с ними не только крупным корпорациям, но и специализированным компаниям и даже стартапам. В последние пару лет появилась масса небольших исследовательских команд, насчитывающих несколько человек и не обладающих гигантскими финансовыми возможностями, которые тем не менее умудряются предлагать новые и перспективные идеи и конкретные работающие решения, построенные на базе ИИ. Один из самых известных примеров – это стартап, создавший очень популярное мобильное приложение Prisma — команда разработчиков сделала сервис для обработки фотографий со стилизацией под того или иного художника.
Массовое развитие и внедрение ИИ сразу во множестве направлений стало возможным благодаря сразу нескольким ключевым факторам развития ИТ-отрасли: проникновению высокоскоростного Интернета, существенному росту производительности и доступности современных компьютеров с одновременным снижением стоимости владения, развитию «облачных» решений и мобильных технологий, росту рынка свободного программного обеспечения (СПО).
Наиболее восприимчивыми к использованию ИИ считаются отрасли массового и распределенного обслуживания потребителей, такие как реклама, маркетинг, торговля, телеком, государственные услуги, страхование, банковское дело и финтех. Дошла волна изменений и до таких консервативных сфер деятельности, как образование и здравоохранение.
Что же такое искусственный интеллект?
В начале 80-х гг. ученые в области теории вычислений Барр и Файгенбаум предложили следующее определение ИИ: «Искусственный интеллект — это область информатики, которая занимается разработкой интеллектуальных компьютерных систем, то есть систем, обладающих возможностями, которые мы традиционно связываем с человеческим разумом, — понимание языка, обучение, способность рассуждать, решать проблемы и т. д.».
Джефф Безос, CEO Amazon, так пишет об ИИ: «За последние десятилетия компьютеры автоматизировали многие процессы, которые программисты могли описать через точные правила и алгоритмы. Современные техники машинного обучения позволяют нам делать то же самое с задачами, для которых намного сложнее задать четкие правила».
Фактически, в настоящее время к искусственному интеллекту относят различные программные системы и применяемых в них методы и алгоритмы, главной особенностью которых является способность решать интеллектуальные задачи так, как это делал бы размышляющий над их решением человек. К числу наиболее популярных направлений применения ИИ относятся прогнозирование различных ситуаций, оценка любой цифровой информации с попыткой дать по ней заключение, а также анализ различных данных с поиском скрытых закономерностей (data mining).
Подчеркнем, что в настоящее время компьютеру не под силу моделировать сложные процессы высшей нервной деятельности человека, такие как проявление эмоций, любовь, творчество. Это относится к сфере так называемого «сильного ИИ», где прорыв ожидается не ранее 2030-2050 годов.
Вместе с тем, компьютером успешно решаются задачи «слабого ИИ», выступая в роли кибернетического автомата, работающего по предписанным человеком правилам. Растет число успешно внедренных проектов т.н. «среднего ИИ», где ИТ система имеет элементы адаптивного самообучения, совершенствуясь по мере накопления первичных данных, по-новому реклассифицируя текстовые, графические, фото/видео, аудио данные и т.п.
Нейронные сети и машинное обучение – основные понятия ИИ
На сегодняшний день накоплены и систематизированы самые разнообразные подходы и математические алгоритмы для построения систем ИИ, такие как байесовские методы, логистическая регрессия, метод опорных векторов, решающие деревья, ансамбли алгоритмов и т.д.
В последнее время ряд экспертов приходит к выводу, что большинство современных и действительно удачных реализаций – это решения, построенные на технологии глубоких нейронных сетей (deep neural networks) и глубокого машинного обучения (deep learning).
Нейронные сети (neural networks) основаны на попытке воссоздать примитивную модель нервных систем в биологических организмах. У живых существ нейрон — это электрически возбудимая клетка, которая обрабатывает, хранит и передает информацию с помощью электрических и химических сигналов через синаптические связи. Нейрон имеет сложное строение и узкую специализацию. Соединяясь друг с другом для передачи сигналов с помощью синапсов, нейроны создают биологические нейронные сети. В головном мозге человека насчитывается в среднем около 65 миллиардов нейронов и 100 триллионов синапсов. По сути – это и есть базовый механизм обучения и мозговой деятельности всех живых существ, т.е. – их интеллект. Например, в классическом опыте Павлова каждый раз непосредственно перед кормлением собаки звонил колокольчик, и собака быстро научилась связывать звонок колокольчика с пищей. С физиологической точки зрения результатом опыта в ее мозгу стало установление синаптических связей между участками коры головного мозга, ответственными за слух, и участками, ответственными за управление слюнными железами. В итоге при возбуждении коры звуком колокольчика у собаки начиналось слюноотделение. Так собака обучилась реагировать на поступающие из внешнего мира сигналы (данные) и делать «правильный» вывод.
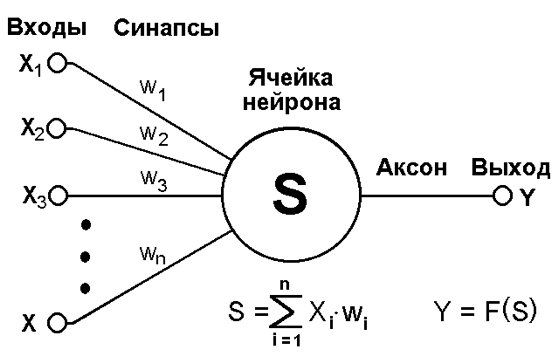
Искусственный нейрон
Именно способность биологических нервных систем обучаться и исправлять свои ошибки легла в основу исследований в области искусственного интеллекта. Их исходной задачей была попытка искусственно воспроизвести низкоуровневую структуру мозга – т.е. создать компьютерный «искусственный мозг». В результате была предложена концепция «искусственного нейрона» — математической функции, которая преобразует несколько входных фактов в один выходной, назначая для них веса влияния. Каждый искусственный нейрон может взять взвешенную сумму входных сигналов и в случае, если суммарный вход будет превышать определенный пороговый уровень, передать двоичный сигнал дальше.
Искусственные нейроны объединяют в сети — соединяя выходы одних нейронов с входами других. Соединенные и взаимодействующие между собой искусственные нейроны создают искусственную нейронную сеть – определенную математическую модель, которая может быть реализована на программном или аппаратном обеспечении. Говоря совсем упрощенно, нейронная сеть - это просто программа – «черный ящик», которая получает на вход данные и выдает ответы. Будучи построена из очень большого числа простых элементов, нейронная сеть способна решать чрезвычайно сложные задачи.
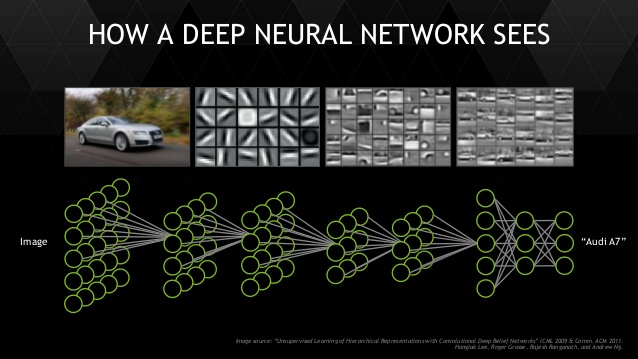
Принцип работы нейронной сети на примере задачи распознавания марки автомобиля в изображении, источник https://wccftech.com/article/nvidia-demo-skynet-gtc-2014-neural-net-based-machine-learning-intelligence/
Математическая модель единичного нейрона (персептрона) была впервые предложена в 1943 году американскими нейрофизиологами и математиками Уорреном Мак-Каллоком, Уолтером Питтсом, они же предложили и определение искусственной нейронной сети. Физически модель при помощи компьютера была смоделирована в 1957 году Френком Розенблаттом. Можно сказать, что нейросети это одна из самых старейших идей практической реализации ИИ.
В настоящее время существует множество моделей реализации нейронных сетей. Есть «классические» однослойные нейронные сети, они применяются для решения простых задач. Однослойная нейронная сеть идентична в математическом смысле обычному полиному, весовой функции, традиционно применяемой в экспертных моделях. Число переменных в полиноме равно число входов сети, а коэффициенты перед переменными равны весовым коэффициентам синапсов.
Есть математические модели, в которых выход одной нейросети направляется на вход другой, и создаются каскады связей, так называемые многослойные нейронные сети (MNN, multilayer neural network) и один из наиболее мощных ее вариантов – сверточные нейронные сети (CNN, convolutional neural network).
MNN обладают большими вычислительными возможностями, но и требуют огромных вычислительных ресурсов. С учетом размещения ИТ систем в облачной инфраструктуре, многослойные нейросети стали доступны большему числу пользователей и в настоящее время они стали фундаментом современных ИИ решений. В 2016 году компания Digital Reasoning из США, занимающаяся когнитивными вычислительными технологиями, создала и обучила нейронную сеть, состоящую из 160 миллиардов цифровых нейронов. Это значительно мощнее нейросетей, имеющихся в распоряжении компаний Google (11,2 миллиарда нейронов) и Национальной лаборатории США в Ливерморе (15 миллиардов нейронов).
Другой интересной разновидностью нейросетей являются нейронные сети с обратной связью (RNN, recurrent neural network), когда выход со слоя сети подается обратно на один из входов. У таких платформ есть «эффект памяти» и они способны отслеживать динамику изменений входных факторов. Простой пример – улыбка. Человек начинает улыбаться с еле заметных движений мимических мышц глаз и лица, прежде чем явно покажет свои эмоции. RNN позволяет обнаружить такое движение еще на ранних фазах, что бывает полезно для прогнозирования поведения живого объекта во времени посредством анализа серии изображений или конструировании последовательного потока речи на естественном языке.
Машинное обучение (machine learning) — это процесс машинного анализа подготовленных статистических данных для поиска закономерностей и создания на их основе нужных алгоритмов (настройки параметров нейронной сети), которые затем будут использоваться для прогнозов.
Созданные на этапе машинного обучения алгоритмы позволят в дальнейшем компьютерному искусственному интеллекту сделать корректные выводы на основании предоставленных ему данных.
Различают 3 основных подхода к машинному обучению:
- обучение с учителем
- обучение с подкреплением
- обучение без учителя (самообучение)
В обучении с учителем используются специально отобранные данные, в которых уже известны и надежно определены правильные ответы, а параметры нейронной сети подстраиваются так, чтобы минимизировать ошибку. В этом способе ИИ может сопоставить правильные ответы к каждому входному примеру и выявить возможные зависимости ответа от входных данных. Например, коллекция рентгенологических снимков с указанными заключениями будет являться базой для обучения ИИ – его «учителем». Из серии полученных моделей человек в итоге выбирает наиболее подходящую, например, по максимальной точности выдаваемых прогнозов.
Нередко подготовка таких данных и ретроспективных ответов требует большого человеческого вмешательства и их ручного отбора. Также, на качество полученного результата влияет субьективность человека-эксперта. Если по каким-либо соображениям – он не рассматривает при тренировке всю совокупность выборки и ее атрибутов, его понятийная модель ограничена текущим уровнем развития науки и техники, указанной «слепотой» будет обладать и полученное ИИ решение. Важно отметить, что нейросети являются функцией с нелинейными преобразованиями и обладают гиперспецифичностью - результат работы алгоритма ИИ будет непредсказуем, если на вход будут поданы параметры, выходящие за границы значений обучающей выборки. Поэтому важно обучать ИИ систему на примерах и частотности, адекватных последующим реальным условиям эксплуатации. Сильно влияет географический и социо-демографический аспект, что, в общем случае, не позволяет использовать без потери точности математические модели, натренированные на популяционных данных других стран и регионов. За репрезентативность обучающей выборки также отвечает эксперт.
Самообучение применяется там, где нет заранее заготовленных ответов и алгоритмов классификации. В этом случае ИИ ориентируется на самостоятельное выявление скрытых зависимостей и поиск онтологии. Машинное самообучение позволяет распределить образцы по категориям за счет анализа скрытых закономерностей и «автовосстановления» внутренней структуры и природы информации. Это позволяет исключить ситуацию системной «слепоты» врача или исследователя. Допустим в ситуации, когда они разрабатывают модель ИИ прогноза сахарного диабета 2-го типа, сосредотачивая основное внимание на показателях глюкозы в крови или весе пациента. Однако одновременно, они вынужденно игнорируют всю другую информацию из истории болезни, которая также могла бы быть полезна. Глубокий подход к обучению позволяет тренировать ИИ на всей многомиллионной базе пациентов и проанализировать любой тест, который когда-либо был записан о пациенте в его электронной медицинской карте.
Механизмы глубокого машинного обучения (deep learning) используют, как правило, многослойные нейросети и очень большое число экземпляров объектов для тренировки нейронной сети. Число записей в обучающей выборке должно насчитывать сотни тысяч или даже миллионы примеров, а когда ресурсы не ограничены – и больше. Для того, чтобы научить ИИ распознавать лицо человека на фотографии, команде разработчиков в Facebook потребовались миллионы изображений с мета-данными и тегами, говорящими о наличии лица на фото. Успех Facebook в реализации функции распознавания лиц как раз лежал в огромном количестве исходной для обучения информации: в социальной сети имеются аккаунты сотен миллионов людей, которые выкладывали гигантское количество фотографий и при этом указывали на них лица и отмечали (идентифицировали) людей. Глубокое машинное обучение на основе такого количества данных позволило создать надежный искусственный интеллект, который теперь за считанные миллисекунды не просто обнаруживает лицо человека на изображении, но и достаточно часто угадывает – кто именно изображен на фотографии.
Большое количество записей обучающей выборки необходимо ИИ и для создания необходимых правил классификации. Чем больше разнородных данных будет загружено в систему на этапе машинного обучения, тем точнее будут выявлены эти правила, и тем в конечном итоге точнее будет результат работы ИИ. Например, при обработке рентгенограмм и МРТ многослойные нейросети способны по изображениям составить представление об анатомии человека и его органах. Вместе с тем, придумать в своей компьютерной классификации названия органов, аналогичные классической врачебной терминологии, компьютеры не смогут. Поэтому им на первых порах требуется «переводчик» с внутреннего машинного словаря на профессиональную лексику.
Также следует учесть, что из-за нелинейности у многослойных нейросетей нет «обратной функции», т.е. компьютер в общем случает не сможет объяснить человеку, почему он пришел к такому выводу. Для подготовки мотивированного суждения нужен человек-эксперт, либо, как ни парадоксально, другая нейросеть, натренированная на задачи написания корректных расшифровок и заключений на естественном человеческом языке.
Метод обучения с учителем более удобен и предпочтителен в тех ситуациях, когда есть накопленные и достоверные ретроспективные исходных данные: обучение на их основе потребует меньше затрат времени и позволит быстрее получить работающее ИИ-решение. Там, где возможность получить базу данных с сопоставленной информацией и ответами на нее отсутствует – необходимо применять методы самообучения на основе глубокого машинного обучения, такие решения не будут нуждаться в надзоре человека.
Нам представляется, что исследователям и стартапам, только начинающим знакомится с ИИ и ищущим возможности его применения в здравоохранении, целесообразно начать именно с методов машинного обучения с учителем. Это потребует меньше затрат (временных, финансовых) на создание прототипа работающей системы и практическое освоение методик ИИ. Функционирующую систему ИИ под конкретную задачу в этом случае можно получить быстрее. В настоящее время на рынке есть большое число качественных библиотек программного кода для искусственных нейросетей, таких как TensorFlow https://www.tensorflow.org/ для математического моделирования, OpenCV http://opencv.org/ для задач распознавания изображений, поставляемых бесплатно, по лицензии «свободное программное обеспечение».
Кроме практического эффекта в повышенной точности, которая сегодня может достигать 95%, системы ИИ в момент обработки данных имеют и высокую скорость работы. Неоднократно проводились эксперименты, например, по распознаванию образов с разных ракурсов, в которых соревновались человек и компьютер. Пока темп показа изображений был невысокий – 1-2 кадра в минуту, человек безусловно выигрывал у машины. При анализе изображений патологии ошибка человека составляла не более 3,5%, а компьютер давал ошибку диагностики 7,5%. Однако, при повышении темпа до 10 кадров в минуту и выше, у человека ослабевала реакция, наступала утомляемость, что приводило к полному браку в работе. Компьютер же непрерывно учился на своих ошибках и в следующей серии только повышал точность работы. Перспективным оказался режим парной работы человека и компьютера, при котором удалось повысить точность диагностики на 85% на относительно высокой для человека скорости демонстрации изображений.
Разумеется, нельзя говорить об эффективном построении моделей ИИ и их точности, если отсутствует необходимая отечественная оцифрованная информация для их обучения. Поэтому критически важно, пусть даже в режиме не полного отказа от классического бумажного документооборота, а дублирования медицинского документооборота и в бумажной, и в электронной форме, начинать накапливать российские банки электронных данных. И дать возможность использовать их в обезличенном виде, без разглашения персональных данных пациентов, для создания и совершенствования отечественных ИИ решений.
Чем отличается создание ИИ от обычной разработки ПО?
Главное отличие методов искусственного интеллекта от обычного программирования состоит в том, что при создании ИИ программисту не нужно знать все зависимости между входными параметрами и тем результатом, который должен получится (ответом). Там, где такие зависимости хорошо известны или где есть надежная математическая модель, например, расчет статистического отчета или формирование реестра на оплату медицинской помощи, вряд ли стоит искать применение искусственному интеллекту – современные программные продукты справляются с задачей пока лучше, надежнее и в приемлемое время.
Технология глубокого машинного обучения эффективна там, где нельзя задать четкие правила, формулы и алгоритмы для решения задачи, например, «есть ли на рентгенологическом снимке патология?». Эта технология предполагает, что вместо создания программ для расчета заранее заданных формул, машину обучают с помощью большого количества данных и различных методов, которые дают ей возможность выявить эту формулу на основе эмпирических данных и тем самым научиться выполнять задачу в будущем. При этом команда разработчиков трудится именно над подготовкой данных и обучением, а не над попыткой написать программу, которая будет как-то анализировать снимок по заранее заданным алгоритмам и получать ответ – так есть на нем аномалия или нет?
Появился целый класс информационных систем, получивших обозначение «IT+DT+AI+IOT», или Цифровые платформы, построенных на данной парадигме. Сокращение «IT» в них обозначает всеобщую цифровизацию процессов и компьютеризацию рабочих мест, «DT» - накопление данных и использование технологий мощной обработки информации, а «AI» - говорит о том, что на накопленных данных будут создаваться роботизированные алгоритмы ИИ, которые будут действовать как в партнерстве с человеком, так и самостоятельно. Сокращение «IOT» означает «интернет вещей» (internet of things) — вычислительная сеть, состоящая из физических предметов («вещей»), оснащённых встроенными технологиями для взаимодействия друг с другом или с внешней средой. Создание цифровых платформ для нужд здравоохранения стоит в числе стратегических приоритетных задач перед развитыми экономиками мира, включая Россию.
Риски и опасения, связанные с ИИ
Вместе с лавинообразным ростом публикаций про перспективы ИИ и появлением все новых и новых примеров создания ИТ-решений на его основе, возрастает и число высказываний экспертов, озабоченных последствиями, которые могут наступить в ближайшие годы и десятилетия от их внедрения.
Опасения экспертов заключаются в том, что, хотя искусственный интеллект и принесет радикальное повышение эффективности в различных отраслях, для простых людей это приведет к безработице и неопределенностям в карьере, поскольку их «человеческие» рабочие места заменяются машинами.

Профессор Стивен Хокинг говорит: «Автоматизация ускорит и без того растущее экономическое неравенство во всем мире … Интернет и платформы, которые делают это возможным, позволяют небольшим группам людей получать огромные прибыли при использовании очень небольшого количества помощников. Это неизбежно, это прогресс, но он также является социально разрушительным».
И такие опасения возникают не на пустом месте. Например, американская компания Goldman Sachs уже заменила трейдеров, занимавшихся торговлей акциями по поручению крупных клиентов банка, на автоматически работающий бот на базе ИИ. Сейчас из 600 человек, работавших в 2000 году, осталось два — остальных заменили торговые роботы, к обслуживанию которых привлечено 200 инженеров. Подробнее http://www.zerohedge.com/news/2017-02-13/goldman-had-600-cash-equity-traders-2000-it-now-has-2
На электронной площадке Amazon арбитражем взаимных претензий покупателей и продавцов товаров занимаются программы-роботы. Они обрабатывают свыше 60 млн. претензий в год, что почти в 3 раза больше числа всех поданных исков через традиционную судебную систему США.
Разумным видятся аргументы сторонников умеренного внедрения ИИ и роботов, сдерживая темп их внедрения т.н. «налогом на роботов». Собираемые с каждого нового роботизированного рабочего места налоги могли бы пойти на финансирование программ обучения, переквалификации и трудоустройства высвобождаемых сотрудников.
Вероятно, такие же перемены следует ожидать и в сфере здравоохранения, хотя для нашей страны – возможно это и будет в чем-то даже благом, учитывая серьезную проблему кадрового дефицита, огромную территорию и низкую плотность проживания населения.
Какие именно задачи можно поручать ИИ?
Andrew Ng, работавший в Google Brain team и лаборатории искусственного интеллекта Стэнфорда (Stanford Artificial Intelligence Laboratory), говорит о том, что в настоящее время СМИ и шумиха вокруг ИИ иногда придают этим технологиям нереалистическую силу. На самом деле реальные возможности применения ИИ достаточно ограничены: современный ИИ пока способен давать точные ответы лишь на простые вопросы.
Совместно с большим объемом исходных данных для обучения, именно реальная и посильная постановка задачи являются важнейшим условием будущего успеха или провала ИИ проекта. Пока ИИ не может решать сложные задачи, непосильные и врачу, вроде создания фантастического прибора, самостоятельно сканирующего человека и способного поставить ему любой диагноз и назначить эффективное лечение. Сейчас ИИ способен скорее решать более простые задачи, например, оценить – присутствует ли инородное тело или патология на рентгенологическом снимке или ультразвуковом изображении? Имеют ли раковые клетки в цитологическом материале? и т.д. Но неуклонный рост точности диагностики посредством ИИ модулей заставляет задуматься. В публикациях уже заявлялись полученные значения точности ИИ до 93% при обработке радиологических изображений, МРТ, маммограм; до 93% точности при обработке пренатальных УЗИ; до 94,5% в диагностике туберкулеза; до 96,5% в предсказании язвенных инцидентов.

По мнению одного из мировых гуру Andrew Ng, реальные возможности ИИ на данное время можно оценить таким простым правилом: «Если обычный человек может выполнить мысленную задачу за секунды, то мы можем, вероятно, автоматизировать ее с помощью ИИ или сейчас, или в ближайшем будущем».
Конкретные алгоритмы или даже решения – не самое главное в успехе ИИ в медицине. Примеры успешных идей публикуются открыто, а программное обеспечение уже сейчас доступно по модели СПО. Например, DeepLearning4j (DL4J) - https://deeplearning4j.org/, Theano - http://deeplearning.net/software/theano/ , Torch - http://torch.ch/ , Caffe - http://caffe.berkeleyvision.org/ и ряд других.
Интересным подходом к разработке ИИ решений является подход краудсорсинга – посредством коллективного экспертного обсуждения. Так на площадке Kaggle https://www.kaggle.com/ на 2017 г. зарегистрировано свыше 40 тыс. экспертов- «датасциентистов» со всего мира, которые решают там задачи ИИ, поставленные коммерческими и общественными организациями. Качество полученных решений порой бывает выше качества разработок коммерческих компаний. Участники с площадки зачастую мотивированы не денежным призом (его может и не быть) за успешное решение проблемы, а профессиональным интересом к задаче и повышением своего личного рейтинга, как эксперта. Краудсорсинг позволяет сэкономить финансы и время для разработчиков и заказчиков, только начинающих работать с ИИ.
На самом деле, только 2 аспекта являются основными барьерами перед более массовым применением ИИ в здравоохранении: большое количество данных для обучения и профессиональный и креативный подход к тренировке ИИ. Без выверенных и качественных данных ИИ не будет работать, именно они являются первой серьезной сложностью для внедрения. Без талантливых людей простое применение готовых алгоритмов к подготовленным данным также не будет давать результат, т.к. ИИ необходимо будет настроить на понимание этих данных для решения конкретной прикладной задачи.
Искусственный интеллект в медицине сегодня
Направление медицины и здравоохранения уже сегодня считается одним из стратегических и перспективных с точки зрения эффективного внедрения ИИ. Использование ИИ может массово повысить точность диагностики, облегчить жизнь пациентам с различными заболеваниями, повысить скорость разработки и выпуска новых лекарств и т.д.
Пожалуй, самым крупным и наиболее обсуждаемым проектом применения ИИ в медицине является американская корпорация IBM и ее когнитивная система IBM Watson. Первоначально это решение стали обучать и затем применять в онкологии, где IBM Watson уже длительное время помогает ставить точный диагноз и находить эффективный способ излечения для каждого из пациентов.
Для обучения IBM Watson было проанализировано 30 млрд медицинских снимков, для чего корпорации IBM пришлось купить компанию Merge Healthcare за 1 млрд. долл. К этому процессу потребовалось добавиться 50 млн. анонимных электронных медицинских карт, которые IBM получила в свое распоряжение, купив стартап Explorys.

В 2014 году IBM объявила о сотрудничестве с Johnson & Johnson и фармацевтической компанией Sanofi для работы над обучением Watson пониманию результатов научных исследований и клинических испытаний. По утверждению представителей компании, это позволит существенно сократить время клинических испытаний новых лекарств, а врачи смогут давать лекарства, наиболее подходящие конкретному пациенту. В том же 2014 году IBM объявила о разработке программного обеспечения Avicenna, способного интерпретировать и текст, и изображения. Для каждого типа данных используются отдельные алгоритмы. Так что в итоге Avicenna сможет понимать медицинские снимки и записи, и будет выполнять функции ассистента радиолога. Над похожей задачей работает и другой проект IBM — Medical Sieve. В данном случае речь идет о развитии искусственного интеллекта «медицинского ассистента», который сможет быстро анализировать сотни снимков на предмет отклонения от нормы. Это поможет радиологам и кардиологам заняться теми вопросами, в которых искусственный интеллект пока бессилен.
Недавно разработчики IBM совместно с Американской кардиологической ассоциацией приняли решение расширить возможности Watson, предложив помощь системы и кардиологам. По задумке авторов проекта, когнитивная облачная платформа в рамках этого проекта будет анализировать огромное количество медицинских данных, имеющих отношение к тому либо иному пациенту. В число этих данных входят изображения с УЗИ, рентгеновские снимки и все прочая графическая информация, позволяющая уточнить диагноз человека. В самом начале возможности Watson будут использоваться для поиска признаков стеноза аортального сердечного клапана. При стенозе отверстие аорты сужается за счет сращивания створок её клапана, что препятствует нормальному току крови из левого желудочка в аорту. Проблема в том, что выявить стеноз клапана не так и просто, несмотря на то, что это очень распространённый порок сердца у взрослых (70-85 % случаев среди всех пороков). Watson попытается определить, что он «видит» на медицинских изображениях: стеноз, опухоль, очаг инфекции или просто анатомическую аномалию – дать соответствующую оценку лечащему врачу, чтобы ускорить и повысит качество его работы.
Врачи Boston Children’s Hospital, занимающиеся редкими детскими болезнями, используют IBM Watson, чтобы ставить более точные диагнозы: искусственный интеллект будет искать необходимую информацию в клинических базах данных и научных журналах, которые хранятся в медицинском облаке Watson Health Cloud, http://www.healthcareitnews.com/news/boston-childrens-ibm-watson-take-rare-diseases

Кристофер Уолш, доктор медицинских наук, директор отдела генетики и геномики Бостонской детской больницы, работает с системой Watson for Genomics, источник https://www.cbsnews.com/news/ibm-watson-boston-childrens-combat-rare-pediatric-diseases/
Следует отметить, что проект Watson, как и любой новаторский продукт, не ставил перед создателями явные экономические цели. Затраты на этапы создания его компонент обычно превышали плановые, а его содержание весьма обременительно, если сравнивать с традиционными бюджетами в здравоохранении. Скорее его можно рассматривать как некий испытательный полигон, на котором можно обкатывать перспективные ИТ технологии и вдохновлять исследователей. А затем, уже проверенные и испытанные прототипы следует переводить в серийное производство, добиваясь более высоких показателей цена-качество и пригодности к эксплуатации в реальных условиях. Почти на каждой конференции по ИИ сегодня звучат доклады от исследователей стран мира с заявлениями «Мы делаем свой Watson, и он будет лучше оригинала».
С помощью системы искусственного интеллекта Emergent исследователям удалось выявить пять новых биомаркеров, на которые могут быть нацелены новые лекарства при лечении глаукомы. По словам ученых, для этого в систему ИИ вводится информация о более чем 600 тыс. специфических последовательностей ДНК 2,3 тыс. пациентов и данные о генных взаимодействиях.
Проект DeepMind Health, который ведет британская компания, входящая в состав Google создала систему, которая способна за несколько минут обработать сотни тысяч медицинских записей и выделять из них нужную информацию. Хотя этот проект, основанный на систематизации данных и машинном обучении, находится еще на ранней стадии, DeepMind уже сотрудничает с Глазной больницей Мурфильдса (Великобритания) с целью повышения качества лечения. Используя миллион анонимизированных, полученных с помощью томографа изображений глаз, исследователи стараются создать алгоритмы на базе технологий машинного обучения, которые бы помогали обнаружить ранние признаки двух глазных заболеваний - влажной возрастной макулярной дистрофии и диабетической ретинопатии. Похожим занимается и другая компания, входящая в Google - Verily. Специалисты этой фирмы используют искусственный интеллект и алгоритмы поисковика Google для того, чтобы проанализировать, что же делает человека здоровым.
Израильская компания MedyMatch Technology, в штате которой насчитывается всего 20 человек, разработала на базе ИИ и Big Data решение, благодаря которому врачи могут точнее диагностировать инсульт. Для этого в режиме реального времени система MedyMatch сравнивает снимок мозга пациента с сотнями тысяч других снимков, которые есть в ее «облаке». Известно, что инсульт может быть вызван двумя причинами: кровоизлиянием в головной мозг и тромбом. Соответственно, каждый из этих случаев требует разного подхода в лечении. Однако, по статистике, несмотря на улучшение в области КТ, количество ошибок при постановке диагноза за последние 30 лет не изменилось и составляет приблизительно 30%. То есть, почти в каждом третьем случае врач назначает пациенту неверное лечение, что приводит к печальным последствиям. Система MedyMatch способна отследить мельчайшие отклонения от нормы, которые не всегда способен заметить специалист, таким образом сводя вероятность ошибки в постановке диагноза и назначении лечения к минимуму.
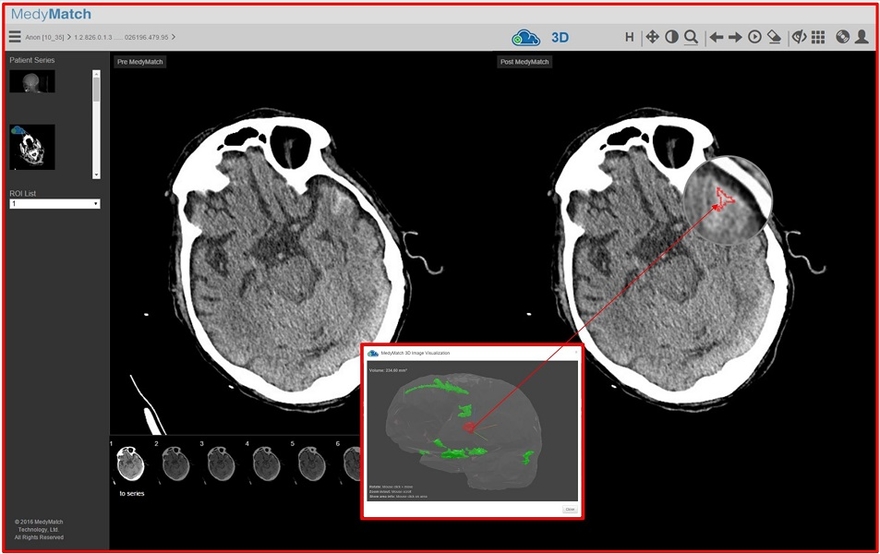
Инструмент MedyMatch, работающий на базе ИИ, помогает командам скорой помощи быстро подтвердить или исключить кровотечение в мозге и провести соответствующее лечение, источник FierceBioTech
Все больше внимания в последнее время уделяется попыткам применять технологии ИИ не только при создании решений для врачей, но и для пациентов. Например, мобильное приложение британской компании Your.MD, запуск которого произошел в ноябре 2015 года. Эта программа использует технологии ИИ, машинного обучения и обработки естественного языка. Это позволяет пациенту просто сказать, к примеру, «У меня болит голова», а затем получить от смартфона рекомендации по последующим действиям и экспертный совет. Для этого система искусственного интеллекта Your.MD подключена к самой большой в мире карте симптомов, созданной все той же Your.MD: в ней учтено 1,4 млн симптомов, на идентификацию которых потребовалось более 350 тыс. часов. Каждый симптом был проверен специалистом британской системы здравоохранения. Искусственный интеллект выбирает наиболее подходящий симптом, основываясь на уникальном профиле владельца смартфона.
Другая компания, Medtronic, предлагает приложение, способное предсказать критическое снижение уровня сахара за три часа до события. Для этого Medtronic совместно с IBM используют технологии когнитивной аналитики к данным глюкометров и инсулиновых помп. С помощью приложения люди смогут лучше понимать влияние ежедневной активности на диабет. В рамках еще одного интересного проекта IBM, на этот раз совместного с диагностической компанией Pathway Genomics, создано приложение OME, объединяющее когнитивную и прецизионную медицину с генетикой. Цель приложения — предоставить пользователям персонализированную информацию для повышения качества жизни. Первая версия приложения включает в себя рекомендации по диете и упражнениям, сведения по метаболизму, которые зависят от генетических данных пользователя, карту с привычками пользователя и информацией о его состоянии здоровья. В будущем должны добавиться электронные медицинские карты, информация о страховке и другие дополнительные сведения.
Дополнительно к прямому клиническому применению, элементы ИИ могут быть использованы и во вспомогательных процессах медицинской организации. Например, уместным будет использовать ИИ при автоматической диагностике качества работы медицинской информационной системы, в вопросах обеспечения информационной безопасности. Системы ИИ могут помочь с выдачей рекомендаций по своевременной настройке справочников, тарифов или даже заметить аномальное поведение сотрудника и порекомендовать его руководителю направить его на обучение работе с системой, так как возникли подозрения в его невысоком профессионализме и замедленной реакции.
Обзор наиболее перспективных направлений развития
Подытоживая вышесказанное, считаем, что уже в ближайшем будущем в здравоохранении будут автоматизироваться при помощи ИИ следующие задачи:
1. Автоматизированные методы диагностики, например, анализ рентгенологических или МРТ-снимков на предмет автоматического выявления патологии, микроскопический анализ биологического материала, автоматическое кодирование ЭКГ, электроэнцефалограмм и т.д. Хранение большого количества расшифрованных результатов диагностического обследования в электронном виде, когда имеются не только сами данные, но и формализованное заключение по ним, позволяют создавать действительно надежные и ценные программные продукты, способные если не заменить врача, то оказать ему эффективную помощь. Например, самостоятельно выявлять и обращать внимание на рутинную патологию, сокращать время и стоимость обследования, внедрять аутсорсинг и дистанционную диагностику.
2. Системы распознавания речи и понимания естественного языка могут оказать существенную помощь как врачу, так и пациенту. Начиная от уже обычной расшифровки речи и превращении ее в текст в качестве более продвинутого интерфейса общения с медицинскими информационными системами (МИС), обращения в Call-центр или голосового помощника – и далее до таких идей, как автоматический языковой перевод при поступлении иностранца, синтез речи при прочтении записей из МИС, робот-регистратор в приемном отделении больницы или регистратуре поликлиники, способный отвечать на простые вопросы и маршрутизировать пациентов и т.д.
3. Системы анализа больших данных и предсказания событий также являются вполне решаемыми уже сейчас задачами для ИИ, которые могут дать существенный эффект. Например, оперативный анализ изменений заболеваемости позволяет быстро предсказать изменение обращаемости пациентов в медицинские организации или потребность в лекарственных препаратах, предупредить эпидемию или дать точный прогноз ухудшения здоровья, что порой может спасти жизнь пациенту.
4. Системы автоматической классификации и сверки информации помогают связать информацию о пациенте, находящейся в различных формах в различных информационных системах. Например, построить интегральную электронную медицинскую карту из отдельных эпизодов, описанных с разной детальностью и без четкого или противоречивого структурирования информации. Перспективной является технология машинного анализа содержимого контента социальных сетей, интернет-порталов с целью быстрого получения социологической, демографической, маркетинговой информации о качестве работы системы здравоохранения и отдельных лечебных учреждений.
5. Автоматические чат-боты для поддержки пациентов могут оказать существенную помощь в повышении приверженности пациентов здоровому образу жизни и назначенному лечению. Уже сейчас чат-боты могут научится отвечать на рутинные вопросы, подсказывать тактику поведения пациентов в простых ситуациях, соединять пациента с нужным врачом в телемедицине, давать рекомендации по диете и т.д. Такое развитие здравоохранения в сторону самообслуживания и большей вовлеченности пациентов в охрану собственного здоровья без визита к врачу может сэкономить существенные финансовые ресурсы.
6. Развитие робототехники и мехатроники. Всем известный робот-хирург Da Vinci – это лишь первый шажочек в сторону если не замены врача на машину, то как минимум повышение качества работы медицинских сотрудников. Интеграция робототехники с ИИ рассматривается сейчас как один из перспективных направлений развития, способный переложить на машины рутинные манипуляции – в том числе и в медицине.
Безусловно, когда идет речь о здоровье человека, важен принцип «не навреди», который должен сопровождаться жесткостью нормативно-правового поля и тщательной доказательной базой при внедрении новых технологий. Вместе с тем, стоит ли заранее относиться к новым технологиям со скепсисом и отрицанием их возможного будущего практического применения, игнорируя очевидные успехи?
Вне зависимости, какая часть решений ИИ в здравоохранении будет успешно внедрена, а какая аргументировано отвергнута, следует признать, что в XXI веке ИИ как технология будет оказывать наибольшее преобразующее влияние, из того пакета технологий, которые мы применяем в медицинской профессии.