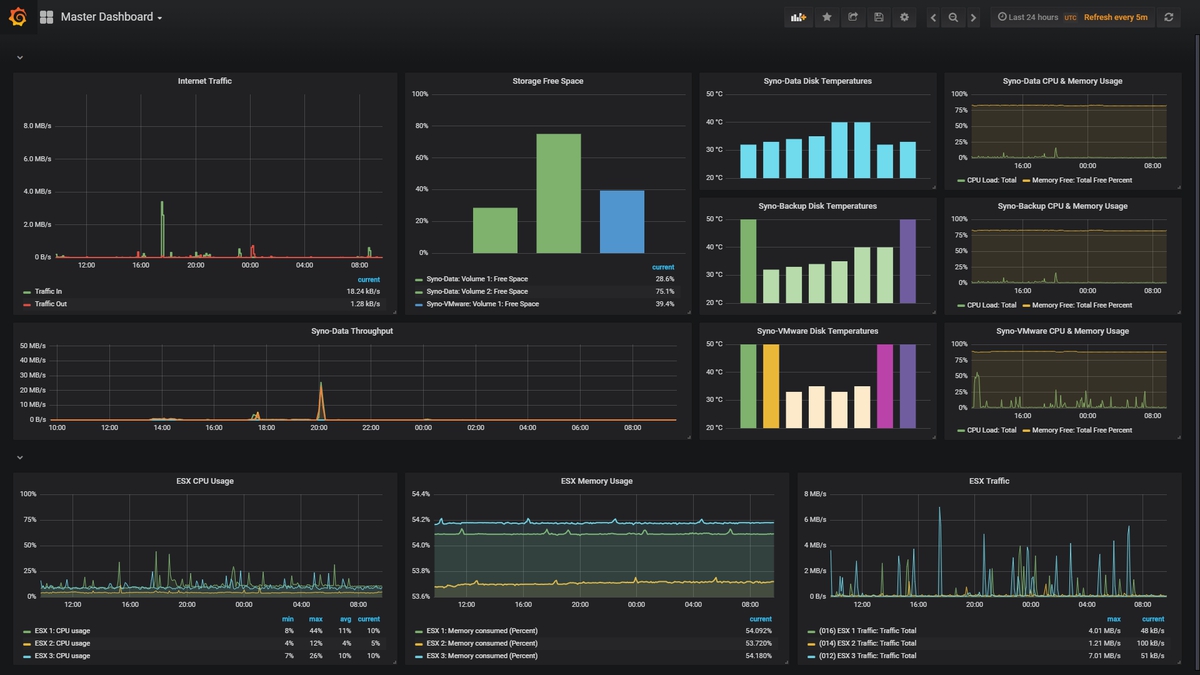
Платформа Webiomed в настоящее время – это достаточно сложная в плане архитектуры информационная система, которая состоит из более 30 микросервисов и которую, в зависимости от нагрузки, реализуют несколько сотен одновременно работающих контейнеров приложений.
Чтобы весь этот комплекс хорошо работал, нам приходится уделять пристальное внимание контролю стабильности и безопасности работы платформы. Для этого внутри компании была создана специальная система мониторинга, в которой в одном месте собраны все ключевые метрики стабильности. Расскажем некоторые подробности как устроен мониторинг нашей платформы.
Что было
Когда проект только начинал свою работу и структурно был достаточно простым, то и с мониторингом было все просто: приложений мало, нагрузка на систему небольшая, использовался инструмент мониторинга Zabbix (https://www.zabbix.com).
Если приходилось делать новую установку системы, то какое-то время приходилось потратить на его настройку, что не было критично. Хоть это и делалось вручную, но имея готовые шаблоны для Zabbix и отлаженную процедуру настройки, это не вызывало каких-то проблем, но ровно до тех пор, пока система не начала стремительно развиваться: начала изменяться архитектура, стали использоваться новые системные приложения, увеличилось количество микросервисов. Как следствие этого, получалось что что-то могло выпасть из наблюдения либо требовалось тратить время на дополнительную настройку мониторинга каждой установки.
Усугубило проблему бизнес-решение о том, что платформа может быть не только облачным сервисом, а еще тиражным решением для установки у заказчиков. Таким образом мы пришли к выводу, что система мониторинга должна стать неотъемлемой частью платформы и при этом иметь следующие свойства:
- Должна работать что называется «из коробки», в идеале вообще не требуя каких-либо специальных действий по установке и настройке.
- Должна развиваться и обновляться синхронно с платформой и автоматически настраиваться в соответствии с архитектурными изменениями.
- Мониторироваться должны все используемые приложения, независимо от того, где, как и в каком количестве они развернуты.
Что используем теперь
Понимая, что мы «переросли» возможности Zabbix, мы решили попробовать альтернативные сервисы и оказалось, что не зря. Мы выявили, что действительно есть инструменты, полностью закрывающие наши потребности.
Мы выбрали и используем современные и доказавшие свою эффективность программные продукты с открытым исходным кодом. Ключевое ПО, реализующее функционал нашей системы мониторинга в настоящее время это:
- Prometheus (https://github.com/prometheus/prometheus/) - агрегатор метрик, собирает метрики и сигнализирует о событиях мониторинга.
- VictoriaMetrics (https://github.com/VictoriaMetrics/VictoriaMetrics) - специализированная СУБД для хранения метрик.
- Alertmanager (https://github.com/prometheus/alertmanager) - отвечает за рассылку уведомлений о событиях мониторинга удобным способом (электронная почта, мессенджеры, веб-хуки).
- Grafana (https://github.com/grafana/grafana) - средство визуализации данных мониторинга в виде диаграмм, графиков, тепловых карт и т.п.
- Loki (https://github.com/grafana/loki) - система агрегации логов.
Дополнительно мы интегрировали в систему мониторинга ряд программ, например экспортеры метрик, которые собирают метрики с приложений, которые не умеют самостоятельно это делать в формате Prometheus. Весь этот программный комплекс и есть то, что мы называем системой мониторинга. Программ здесь действительно относительно много, но зато каждая делает свою работу хорошо, к тому же это позволяет гибко настраивать систему и минимальным риском что-либо испортить. Ничего принципиально нового для создания собственной системы мониторинга изобретать не пришлось, нужно лишь было освоить необходимые инструменты, правильно их скомпоновать и заточить под свои потребности.
Что пришлось сделать
Для Prometheus были сделаны правила авто-обнаружения сервисов, сбора метрик с них и правила сигнализации о проблемах. Сама настройка Prometheus для сбора метрик не является сложной задачей, а вот настройке правил сигнализации пришлось уделить внимание. Это довольно распространенная проблема: если настроить много правил и тем более, если не верно подобрать пороги срабатывания, то можно утонуть в потоке сообщений о том, что в системе что-то не так. При этом как-то реагировать на них обычно не требуется, но зато повышается риск упустить действительно что-то важное. С другой стороны, необходимо сигнализировать обо всех критичных событиях в системе и о точно намечающихся проблемах. При настройке правил сигнализации мы исходили из того, что за системой обязательно следят более-менее постоянно и можно ограничится только действительно важными сообщениями.
Штатная работа по слежению за состоянием системы выглядит так: Alertmanager обычно настраивается на отправку сообщений в какой-нибудь мессенджер, у себя мы отправляем сообщения в выделенный канал корпоративного чата. Ответственные сотрудники следят за сообщениями в нем, что можно делать как с компьютера, так и со смартфона. Если пришло сообщение о проблеме, то уже думаем как реагировать и нужно ли вообще что-то делать. И вместе с этим периодически просматриваются важные дашборды в Grafana. Какие-то смотрим раз в день, какие-то раз в неделю, какие-то еще реже. Но обычно на это тратится совсем немного времени, редко более 10 минут в день.
Grafana, как средство визуализации, в нашей системе мониторинга комплектуется всеми необходимыми дашбордами. Фактически из Grafana можно отследить работу каждого приложения платформы, включая сами инструменты мониторинга. Сообществом сделано больше количество дашбордов под разные приложения, которые распространяются на принципах программного обеспечения с открытым исходным кодом, и готовые дашборды почти полностью были применимы в нашем проекте.
Однако мы выявили нюансы, из-за которых многие дашборды были значительно модифицированы. Например, не везде были сделаны графики нужных нам метрик. Либо визуализация метрики отсутствовала вообще, либо был выбран неудобный на наш взгляд способ визуализации, например, там где мы хотели бы видеть график, разработчик сделал отображение в виде индикатора.
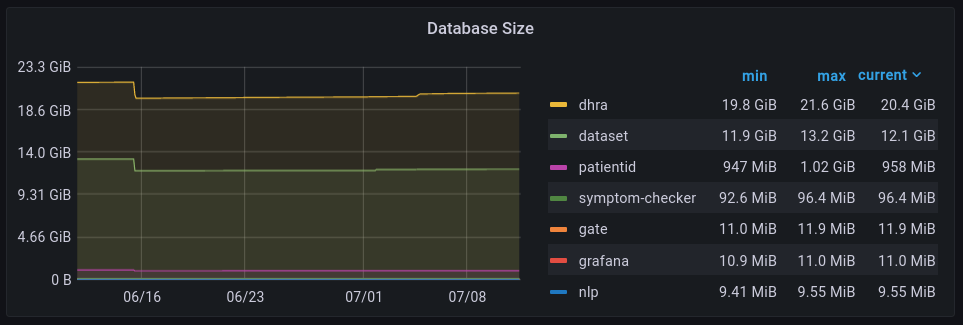
Взять для примера мониторинг СУБД PostgrSQL. Есть хороший дашборд для PostgreSQL (https://grafana.com/grafana/dashboards/9628), но на нем нет очень полезной и важной метрики - размера баз данных. Объяснение тут достаточно простое – у экспортера метрик, который используется в СУБД, по умолчанию размер баз данных не мониторируется. Требуется дополнительная настройка экспортера что бы он мог определять размер баз данных. Как следствие, в своей системе мониторинга мы сразу преднастриваем и экспортер метрик PostgreSQL для возможности отслеживания размера баз и добавляем сам график размера баз данных.
Даже если графики есть, то не всегда они хорошо настроены. Как правило, помимо самого вида графика, нас еще интересуют и показатели за период: минимальное, максимальное, среднее и текущее значение. Это всё можно показать в легенде к графику, но у готовых графиков либо что-то из значений не хватает, либо легенда вообще могла отсутствовать. Пришлось дополнительно настраивать легенды. Для примера, вот как выглядит график использования процессора контейнерами из этого дашборда: https://grafana.com/grafana/dashboards/10619.
Взяв его за основу и добавив вывод показателей за период, стало удобнее искать самые загруженные контейнеры.
Для каких-то приложений приемлемых готовых дашбордов не нашлось и пришлось из создавать с нуля, учитывая наши требования и особенности приложений. Например, полностью был сделан свой дашборд для отслеживания состояния задач резервного копирования баз данных.
Разработчиками Grafana развивается еще и система для агрегации логов приложений - Loki, которую мы задействовали в своем проекте и которая является хорошей альтернативой популярным системам для сбора и анализа логов на основе Elasticsearch. Loki хорош тем, что позволяет работать с логами непосредственно из той же Grafana, которую используем для мониторинга. Вот так, например, выглядит лог работы Apache Kafka.
Что в итоге получилось
Основные цели, которые мы ставили при разработке специализированной системы мониторинга для нашей платформы Webiomed, удалось достигнуть. Она не требует отдельного внимания при установке, настройке и обновлении всей платформы. Единственное, что требуется настроить - это указать канал отправки уведомлений.
Система мониторинга актуализируется синхронно с самой платформой, а так как это фактически набор файлов в репозитории, то обновив исходный код системы мониторинга один раз в репозитории, можно теперь не заниматься настройкой каждой установки после обновления.
Теперь мы вышли на этап оптимизации системы мониторинга. На основании уже полученного опыта становится понятно, что следует улучшать, как правило это касается дашбордов: какие графики метрик добавить, какие наоборот стоит убрать или переместить, потому что ими фактически не пользуемся, но при этом они занимают место на дашбордах и мешают восприятию действительно важных графиков.