
Стандартный жизненный цикл модели машинного обучения представляет собой последовательность нескольких базовых этапов, каждый из которых требует тщательного мониторирования и, в конечном счете, участвует в формировании своего рода циклической структуры за счет периодичности переобучения (рис. 1).
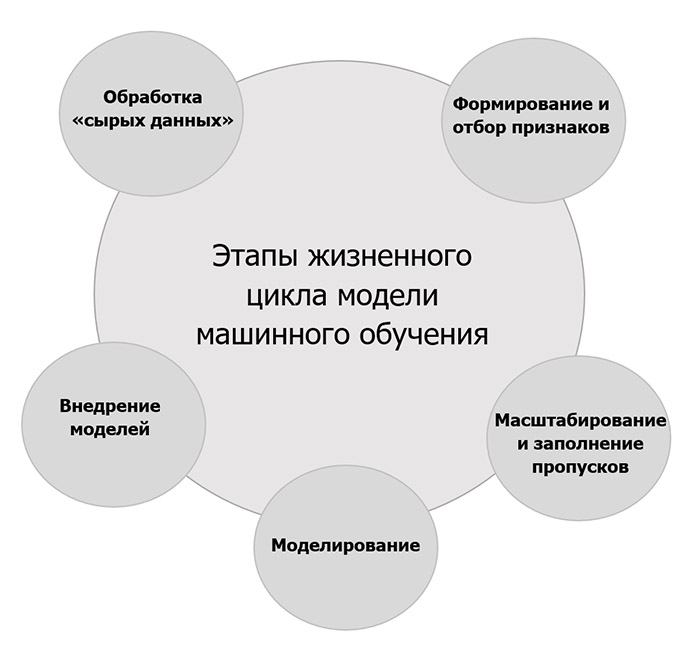
Рис. 1 Стандартный жизненный цикл модели машинного обучения.
Среди таких этапов в классической схеме обычно выделяют обработку «сырых данных», формирование и отбор признаков, нормализацию данных, моделирование на сформированных датасетах и внедрение финальных моделей в практику.
Процесс обработки медицинских данных имеет свою специфику ввиду значительных трудностей на этапе аналитики и статистической обработки информации. Данные, получаемые из различных медицинских учреждений, часто характеризуются большой разрозненностью и плохой структуризацией, что затрудняет создание репрезентативных наборов.
Выявляемые в процессе создания моделей зависимости и разработка новых гипотез требуют постоянного уточнения задач и переобучения алгоритмов, приводя к появлению необходимости в структурном подходе к каждому из этапов жизненного цикла моделей машинного обучения.
Наиболее затратным этапом является работа с «сырыми данными», которая представляет собой получение конечных значений признаков из больших массивов медицинских и сопутствующих данных на основе различных вариантов логики и правил их формирования. Примечателен мультидисциплинарный подход к решению задач на данном этапе: наличие выбросов и низкая заполненность значений признаков требуют тесного взаимодействия со специалистами по базам данных и медицинскими экспертами, лишь совместными усилиями с которыми возможно достичь воспроизводимых результатов, имеющих ценность для повседневной медицинской практики.
Большое значение также имеют последовательное внедрение и поддержка моделей машинного обучения, используемых в производстве.
Мониторинг работы модели в процессе ее использования является обязательным этапом ввиду постепенного деградирования метрик, что особенной важно в оценке работы системы поддержки принятия врачебных решений.
Наиболее вариативным и плохо поддающимся планированию (а значит оценке необходимых ресурсов и времени исполнения) этапом жизненного цикла является непосредственное моделирование, так как все его составляющие (алгоритмы, значения гиперпараметров, настройки обучения и т.п.) должны быть подобраны «вручную» под конкретную задачу. Это также означает, что полученные результаты являются зачастую плохо воспроизводимыми и субъективными (зависят от навыков и опыта конкретного специалиста по машинному обучению).
Однако для успешного решения бизнес-задач производство моделей должно быть максимально прозрачным и предсказуемым процессом, который масштабируем и воспроизводим. Таким образом необходимо стремиться снизить неопределенность творческой составляющей при разработке моделей.
Для того, чтобы сократить неэффективные затраты и повысить качество работы моделей машинного обучения в проекте Webiomed, мы осуществили внедрение технологий AutoML и MLflow в процесс создания моделей.
Применение AutoML при разработке моделей машинного обучения
В реальной клинической практике заполненность медицинских данных зачастую оставляет желать лучшего и требует применения различных методик для их заполнения при моделировании.
Существует множество решений данной проблемы, каждое из которых имеет свою аргументацию и своих сторонников, но в работе, в погоне за лучшими метриками итоговой модели, необходимо проверить все возможные варианты на имеющихся данных. В конечном счете это приводит к огромной вариативности, необходимости сохранения данных с различной обработкой и чревато созданием громоздких, зачастую плохо организованных репозиториев и большим количеством ошибок с плохой воспроизводимостью рабочего процесса. Этот факт, а также необходимость зачастую строить многокомпонентные пайплайны моделирования и комбинировать десятки алгоритмов моделирования для обеспечения требуемых показателей метрик качества требуют поиска новых фрейм-ворков, одним из которых является использование AutoML.
На практике AutoML применяют для решения множества задач - автоматизации подготовки данных, извлечения и отбора признаков или непосредственного обучения моделей. В процессе изучения существующих на рынке решений нами были отобраны для сравнения программные библиотеки PyCaret и Auto-Sklearn.
Среди преимуществ Auto-Sklearn были отмечены ансамблевое построение моделей и высокая точность. Однако, те же сложные ансамбли значительно повышают вероятность переобучения, а скорость обучения при использовании этого пакета значительно ниже, чем у PyCaret. На основе встроенных функций PyCaret формирует структуру обработки исходного датасета, что позволяет избежать ручного выполнения всех преобразований, будь то заполнение пропусков, масштабирование, коррекция дисбаланса классов или снижение размерности данных.
После инициализации выбранного пайплайна мы пользуемся встроенной функцией сравнения поддерживаемых модулем алгоритмов на основе различных метрик качества (рис. 2).
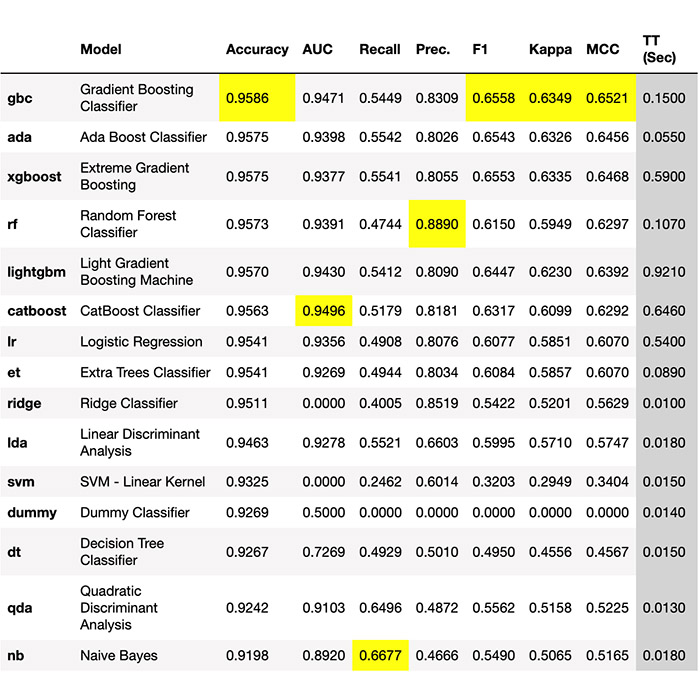
Рис. 2 Встроенная функция сравнения алгоритмов в библиотеке Pycaret. Максимальные значения метрик автоматически выделяются желтым цветом.
Создание выбранной модели в PyCaret является также автоматизированной функцией, принимающей на вход имя выбранного алгоритма и выдающей объект самой модели с результатами ее кросс-валидации. Подбор оптимальных гиперпараметров заложен в структуру модуля, а сам алгоритм их поиска построен на основе Random Grid Search и происходит по заранее сформированной на основе опыта создателей библиотеки сетке значений, которая может при необходимости быть модифицирована.
Возможность визуализации работы финальной модели, оценки важности признаков, интерпретации полученных результатов также являются отличительной особенностью PyCaret. Калибровка выполняется с помощью одной функции после финализации модели. В исходном коде лежит CalibratedClassifierCV из библиотеки sklearn с возможностью использовать параметрическую калибровку Платта или изотоническую регрессию.
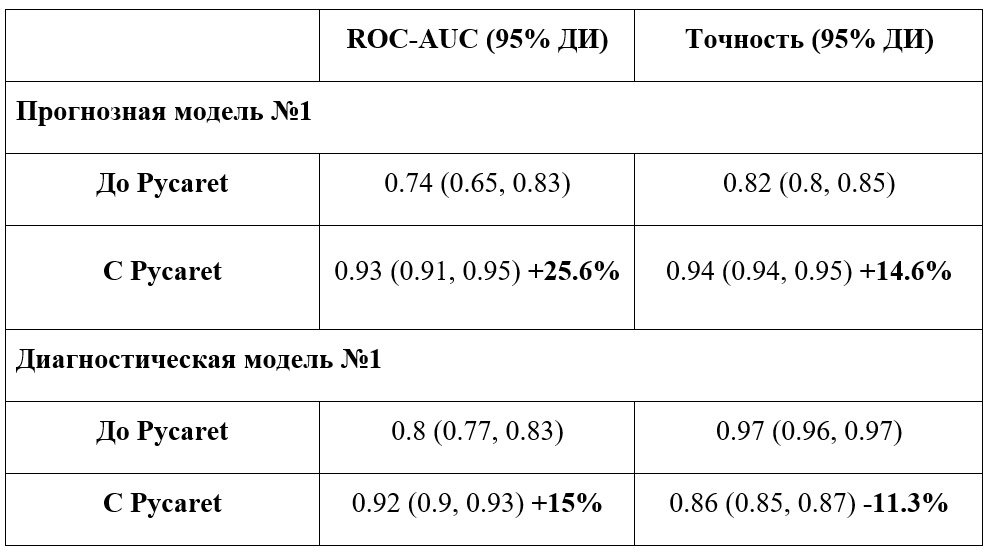
Используемый нами фреймворк PyCaret позволяет полностью автоматизировать процесс разработки моделей с использованием встроенных функций, сразу же сравнивать получаемые метрики качества между нескольким алгоритмами и, что очень важно, действительно тонко настроить параметры этих алгоритмов для поучения наилучших результатов. При сравнительном анализе рабочего процесса до использования Pycaret и после его внедрения было отмечено значительное уменьшение затраченного времени на этапе моделирования (рис. 3) при одновременном повышении значений целевых метрик качества ROC-AUC (табл. 1).
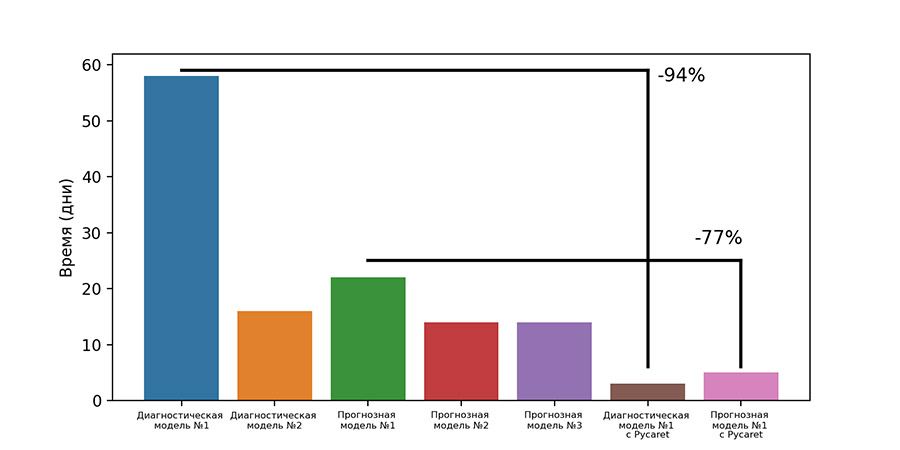
Рис. 3 Затраты времени на этапе моделирования при разработке моделей машинного обучения.
Таблица 1. Значения целевых метрик качества до использования Pycaret и после его внедрения на примере моделей машинного обучения с задачей бинарной классификации.
Место MLflow в разработке моделей машинного обучения
В настоящее время, в процессе разработки моделей машинного обучения практикуется исследование нескольких алгоритмов для сравнения и выбора оптимальной архитектуры. Считается, что при использовании каждого варианта нормализации данных необходимо заново искать оптимальные параметры для всех обучаемых алгоритмов. В итоге каждый из этих алгоритмов должен иметь отдельные версии, оптимально предсказывающие целевое событие именно при определенной обработке входных данных. Это порождает огромное множество версий алгоритмов, в результате чего возникает насущная необходимость в формировании реестров моделей, для чего нами также был взят в работу сервис MLflow.
MLflow — это библиотека с открытым кодом для управления жизненным циклом отдельных экспериментов, каждый из которых представляет собой применение различных архитектур с найденными с помощью Pycaret гиперпараметрами на данных после их нормализации. При использовании данной библиотеки нам удалось создать структуру проекта, где каждая отдельная строка представляет собой информацию об определённой версии алгоритма, делающей предсказания на данных после определенной обработки (рис. 4).
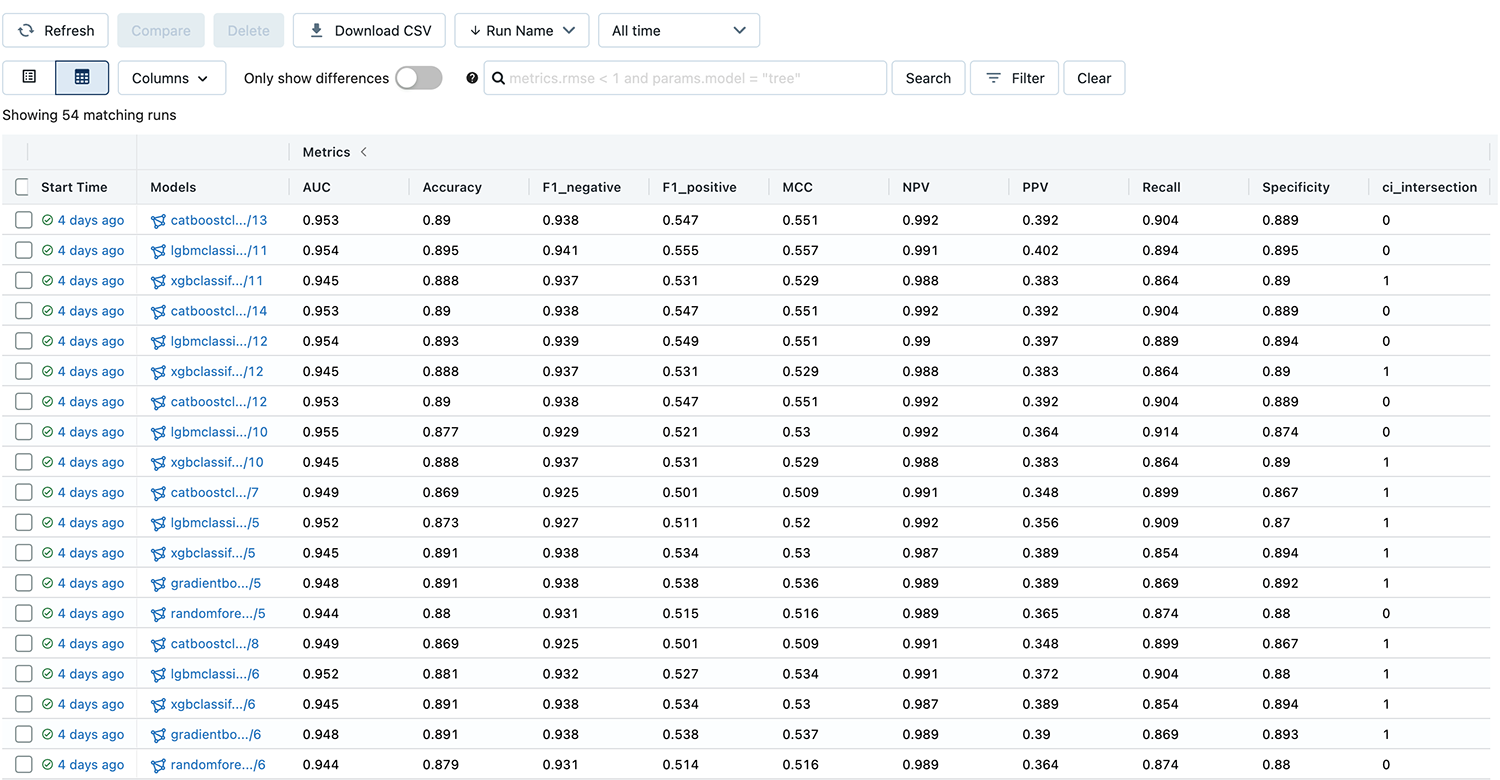
Рис. 4 Структура эксперимента в MLflow
Компактность такой структуры позволяет объективно выбирать оптимальную версию отдельного алгоритма для дальнейшего встраивания на основании значений заранее выделенных метрик и требований технического задания. Большим плюсом MLflow также является возможность сохранять всевозможные артефакты, полученные во время работы, будь то графики для дальнейшей отчетности, параметры модели списком или сама модель в нужном формате для дальнейшего встраивания.
Заключение
Внедрение AutoML и MLflow позволили команде Webiomed полностью фиксировать и стабилизировать процессы обучения и выбора итоговой модели, что гарантирует устранение такой ахиллесовой пяты машинного обучения, как воспроизводимость каждого отдельного эксперимента.
Материал подготовлен командой ИИ-подразделения проекта Webiomed.