

Введение
Внедрение технологий искусственного интеллекта (ИИ) в здравоохранении является одним из самых перспективных направлений цифровой трансформации отрасли. Несмотря на то, что активно о применении ИИ в медицине стали говорить в последние 3-5 лет, на самом деле исследования и разработки в этой сфере ведутся давно, еще с 1970 г. прошлого века. Например, одной из первых система поддержки принятия врачебных решений (СППВР) была система MyCIN, которая с первых версий показала высокую точность постановки предварительного диагноза на основе анализа симптомов и применения передовых на то время разработок в сфере ИИ.
В течение многих лет разработчики предлагали различные сценарии и прикладные продукты на основе ИИ для применения в медицины, довольно часто обещая – что со временем эти продукты полностью изменят здравоохранение. По факту лишь некоторые ИИ-решения показали действительно убедительные способности превзойти врачей, но и то лишь в некоторых узких задачах, таких как поиск патологий в медицинских изображениях, анализе симптомов пациента для постановки диагноза и т.д.
За 1970-2020 гг. было несколько всплесков интереса к применению ИИ, которые как правило имели форму завышенных ожиданий (или обещаний) со стороны разработчиков и довольно низкий уровень их реальных возможностей. Достаточно вспомнить оглушительный провал IBM Watson. Основная причина этих разочарований состояла в том – что на самом деле в ИИ-системах отсутствовало то, что действительно бы напоминало общий интеллект, необходимый и свойственный врачу.
Однако в настоящее время на фоне действительно впечатляющих успехов ChatGPT, созданного компанией OpenAi, интерес к применению ИИ в здравоохранении снова находится на волне постоянно возрастающих ожиданий. Такой очередной всплеск связан с тем, что используемая для создания ChatGPT технология больших языковых моделей (Large Language Models, LLM) позволила получить ИИ-систему, которая действительно очень правдоподобно имитирует человеческий интеллект. Такой ИИ-сервис способен отвечать на любые вопросы, принимать участие в обсуждении любых тем, давать довольно правдоподобные ответы, в том числе и на медицинские темы.
Эта технология заставила организаторов здравоохранения задуматься о том, как они могут использовать LLM и какие риски эта технология представляет для пациентов и врачей.
Базовые определения
Прежде чем приступить к рассмотрению темы LLM в здравоохранении и наиболее перспективных сценариях их применения, крайне важно четко понимать используемые термины и отличия между ними.
Во-первых, необходимо обратить внимание, что условно все технологии ИИ и продукты на их основе разделяются на 2 крупных класса:
- Дискриминативный искусственный интеллект (Discriminative AI) используется для решения задач, связанных с анализом и интерпретацией данных.
Именно эти ИИ-технологии сейчас используются во всех без исключения медицинских изделиях с ИИ, также ИИ-сервисах.
Такой ИИ всегда принимает на вход какой-то набор данных (DICOM-изображение, медицинскую текстовую запись или медицинский документ, аудио-файл, видео-файл, текстовое сообщение пациента и тд) и далее с помощью одной или нескольких моделей машинного обучения интерпретирует полученные данные для решения какой-то конкретной, заранее заданной задачи. Например, отвечает на вопрос – есть в DICOM-изображении признаки патологического процесса или нет (задача классификации)? Если есть – в какой именно области (задача детекции)?
- Генеративный искусственный интеллект (Generative AI, GenAi) создается для принципиально другого применения. Эти технологии предназначены для создания контента на уровне, сопоставим с творческими способностями человека. Включает создание изображение, текстов или мультимедиа в ответ на запрос человека.
Иными словами, самое главное отличие дискриминативного ИИ от генеративного ИИ состоит в том, что первый получает на вход данные, а обратно отдает результат анализа этих данных. А второй (генеративный) – на вход получает команду, а на выход отдает созданный (сгенерированный) внутри ИИ ответ, который должен быть максимально похоже на ответ, который бы дал сам человек.
Общее понятие о генеративном ИИ и больших языковых моделях
Для того, чтобы «научить» ИИ-систему создавать контент на таком уровне имитации, когда мы не можем отличить – был ли этот контент создан действительно человеком или машиной (а именно это качество является главной метрикой и целью развития GenAi), нужны сверхмощные модели машинного обучения.
В настоящее время считается, что для роста мощности моделей, необходимых для задач GenAi, необходимо постоянно увеличивать число параметров (связей, искусственных нейронов), которые содержаться внутри такой модели. Именно поэтому главной технологической базой развития GenAi являются большие генеративные модели (Generative models) — модели машинного обучения, предназначенные для создания мультимодальных данных на основании запросов и содержащие не менее 1 млрд. параметров.
Большие генеративные модели создаются таким образом, чтобы на основании поступившего запроса (который чаще всего называют промптом – prompt) можно было получить адекватный этому запросу контент. Изначально такие модели создавались для определенного вида контента, например – только для создания текстовых ответов или только для создания картинок. Но в настоящее время большинство моделей учатся или как минимум теоретически способны создать мультимодальные данные, например – видеоролик со звуком и человеческой речью или текстовую статью с графиками и иными визуализациями.
Одним из самых популярных и проработанных разновидностей больших генеративных моделей являются большие языковые модели (Large Language Models, LLM) – направление генеративного ИИ, занимающееся созданием языковых моделей, способных генерировать язык общего назначения и выполнять другие задачи обработки естественного языка, такие как например перевод с одного языка на другой или сочинение текстов.
В настоящее время в мире создано уже несколько десятков различных LLM-моделей общего назначения, и мы видим постоянно усиливающуюся конкурентную гонку как в возможностях этих моделей (включая преодоление все новых и новых рекордов в универсальных бенчмарков), так и в технических характеристиках (числе параметров модели).
Как правило, все LLM-модели создаются на основе предварительно обученного преобразователя (GPT). Именно наличие GPT внутри LLM-модели дает ей способность очень точно предугадывать – какое слово или даже предложение надо поставить после поданных на вход в GPT других слов. В итоге GPT создает текст, поразительно точно напоминающий человеческий текст, позволяя тем самым пользователям взаимодействовать с LLM-системой почти так же, как если бы они общались с другим человеком.
Чаще всего вокруг LLM создается специальная «обвязка» - какой-то интерфейс, который отвечает за получение от человека запроса (промпта), отправку его в LLM-модель, получение и возвращение человеку ответа. Такими интерфейсами могут быть чат-боты, в том числе встраиваемые в меседжеры или социальные сети, программные интерфейсы (API) или просто веб-странички в сети интернет.
Люди используют LLM-системы, вводя текстовые вопросы или команды. В ответ они получают созданный LLM-системой текстовый ответ. При этом темы для обсуждения никак не ограничены, поскольку как правило LLM-модели обучаются на универсальных текстах, например – страницах в Интернет, записях в социальных сетях, сообщениях на форумах, книгах, статьях, постах в блогах и т.д.
LLM-модели могут объяснить сложные вопросы, такие как квантовая механика, простыми терминами. В медицине LLM-модели могут написать жалобы или симптомы заболевания или попросить объяснить какое-то лекарство или болезнь – и ответ будет дан на уровне, как будто это объяснение было создано специалистом по данному вопросу.
Основные опасности больших языковых моделей
Главной опасностью LLM является их способность давать настолько правдоподобные ответы на вопросы человека, что при прочтении этих ответов мы в подавляющем большинстве не способы отличить – был ли этот ответ дан ИИ или настоящим человеком.
Такая поразительная имитация создает другой риск – часто общаясь с LLM, мы перестаем держать в голове, что все то нам возвращается – это не информация и не знания, добытые из каких-то баз данных или Интернет. Это именно искусственно придуманный текст, просто написанный очень правдоподобно и в большинстве случаев соответствующий истине. Но – не всегда.
Особенность и даже склонность LLM время от времени придумывать совершенно ложную информацию, называют галлюцинацией ИИ. Это и в самом деле нечто, похожее на речь психически-нездорового человека. Она может быть довольно складной, ничем внешне не отличимой от речи здорового человека. Но по факту – не иметь ничего общего с правдой или реальность. Именно галлюцинации LLM (и генеративного ИИ в целом) являются самой главной опасностью применений этой технологии с точки зрения здравоохранения и медицины, которые как известно – во главу угла ставят принцип «Не навреди».
Примерами галлюцинаций, уже выявленных при использовании LLM, могут быть арифметические ошибки (2 + 2 = 5), придуманные имена авторов или врачей, придуманные названия исследований, придуманные рекомендации по лечению болезней, которые для врача-эксперта будут выглядеть полным бредом, но пациент не сможет это понять в силу отсутствия специальных знаний – и т.д.
В этой связи довольно быстро компании-разработчики общего LLM ограничили их возможности давать ответы на вопросы, если они касались диагностики и назначения лечения.
Краткая характеристика сектора LLM для здравоохранения
Исследования, которые можно так или иначе отнести к сфере LLM для здравоохранения, ведутся не первый год – но, конечно, главный взрыв числа публикаций по этой теме наступил осенью 2023 г. на фоне гипер-успеха ChatGPT.
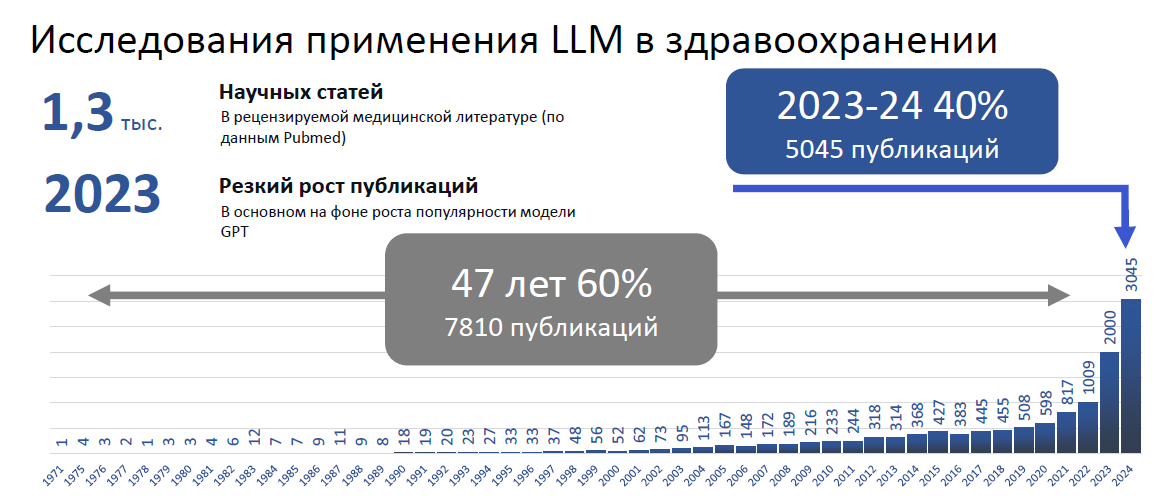
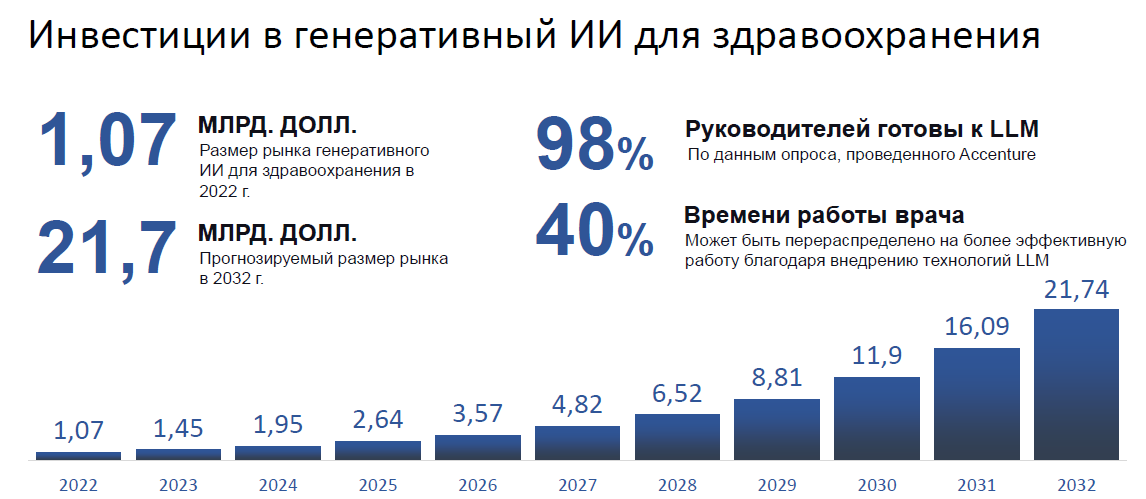
Как только стало понятно, что технические возможности имитировать интеллект человека вышли на принципиально новый уровень и теоретически могут действительно позволить создавать ИИ-агентов, которые полностью могут заменить человека в бизнес-процессах системы здравоохранения, возник бум интереса инвесторов к применению генеративного ИИ (и LLM в частности) для создания коммерческих сервисов для здравоохранения.
Наиболее перспективные сценарии применения LLM в здравоохранения
В настоящее время отсутствует единое мнение или хотя бы существенное совпадение мнений о том, как следует применять LLM в здравоохранении и какие сценарии являются относительно безопасными, но эффективными.
На картинке ниже показаны цитаты из некоторых аналитических отчетов или высказываний опиньен-лидеров по данному вопросу. По этим цитатам видно, насколько расходятся мнения экспертов:

Отслеживая научные публикации, обсуждения на крупных мировых площадках (конференциях) и публикуемой аналитике, были выделены 3 наиболее перспективных и в тоже время относительно контролируемых направлениях применения LLM в здравоохранении:
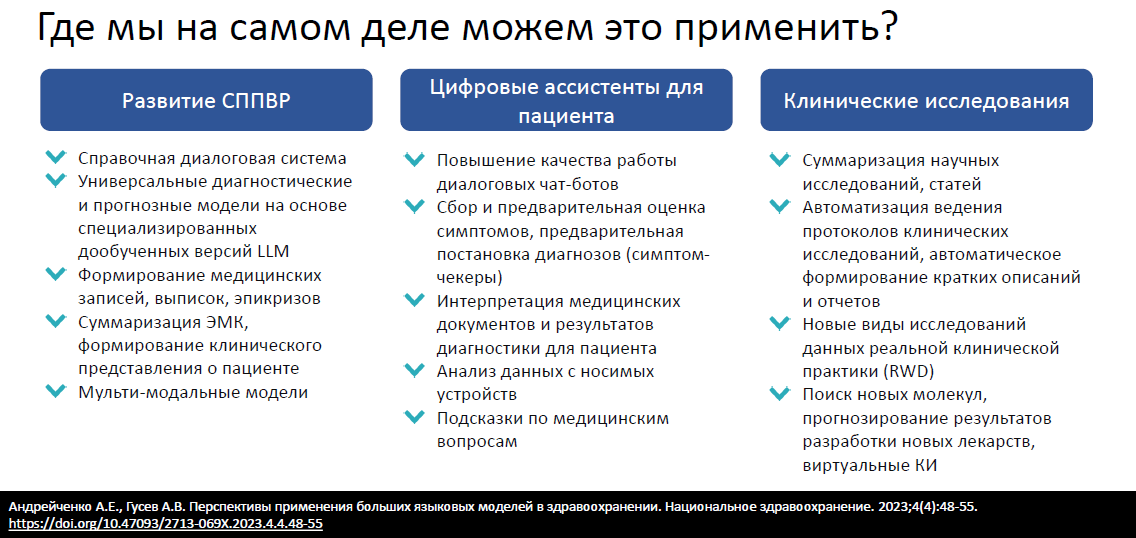
Самой главной темой и задачей для развития данного направления является выявление и оценка возникающих рисков применения LLM, которые крайне сильно отличаются от рисков применения обычного (дискриминативного) ИИ.
На данный момент мы выделяем следующие риски:
- Обеспечение национального суверенитета: нужны национальные открытые LLM для исследований и разработчиков, мы не должны вкладываться в исследования и разработки, созданные на основании продуктов американских и европейских компаний (а других на рынке толком и нет фактически)
- Нужна финансовая поддержка аренды серверных специализированных мощностей для повышения доступности мощных вычислительных ресурсов для создания LLM. Обычные ИИ-разработчики или научные центры просто не в силах финансировать дорогостоящие затраты на создание собственных LLM.
- Соблюдение конфиденциальности данных пациентов, защиты авторских прав и этичного создания и поддержки LLM на всех этапах жизненного цикла моделей. Для этого нужен ЭПР по обезличенным медицинским данных, без такого семпла данных обучение LLM на русском корпусе текстов общего назначения приведет к созданию крайне высоких рисков ошибок в обработке именно специальных медицинских текстов и терминов
- Использование LLM в СППВР требует изменения в законодательстве и техническом регулировании, поскольку сейчас для отнесения ПО к МИ используется термин «интерпретация», которые не работает в случае применения технологий генеративного ИИ (там нет вообще интерпретации)
- Использование LLM приведет к повышению риска применения ИИ, который и так сейчас является максимальным (3й класс). Возможно, требуется особое регулирование и ограничение применения LLM в некоторых сценариях, например – реанимация. Можно было бы также подумать над выделением еще одного, 4го класса риска – именно для LLM-сценариев. Также нужно обязательно переносить в определение МИ продукты, предназначенные для пациентов и использующие LLM – в противном случае есть большой риск причинения вреда пациентам за счет непроверенных LLM-решений, имеющих сильную привлекательность для пациентов за счет своей имитационной возможности заменить общение пациента с реальным врачом
- Отсутствие стандартов и методических рекомендаций и другого мягкого регулирования для LLM. Сейчас любой недобросовестный разработчик на основании ChatGPT может создавать что угодно – и никаких оснований оценивать их действия как неприемлемые – нет.
- Высокие риски галлюцинаций и чрезмерная зависимость от моделей ИИ в образовательных процессах или проведении научных исследований и публикаций
Учитывая перспективность и риски, мы видим – что на данном этапе стратегия развития LLM в здравоохранении могла бы сосредоточится на следующих направлениях:
- Запуск и стимулирование пилотных проектов разработок и внедрения LLM с целью как можно более раннего и всестороннего анализа практического опыта применения данной технологии, включая оценку преимуществ и потенциальных опасностей
- Разработка отдельного технического и нормативного регулирования для продуктов на основе LLM, в том числе с точки зрения их применения в лечебно-диагностических процессах
- Разработка методических рекомендаций для компаний и организаций здравоохранения о том, как они могут внедрять LLM в свои существующие продукты и услуги на основе риск-ориентированного подхода и ответственного отношения к ИИ
- Выработку регуляторных подходов и рекомендаций для проведения различия между LLM, специально обученными на медицинских данных, и LLM, обученными для немедицинских целей
- Отнесение медицинских цифровых приложений для пациентов, использующих технологии LLM и обеспечивающие анализ медицинских данных и рекомендации по здоровью к категории программных медицинских изделий