
Применение технологий искусственного интеллекта в создании различных решений, ориентированных на медицину и здравоохранение, набирает свои обороты. Такие ИИ-системы могут применятся в различных областях, включая диагностику, планирование лечения, консультирование и превентивные меры, а также робототехнику.
Несмотря на присутствие на рынке большого числа различных прикладных решений, создаваемых специализированными компаниями и научно-исследовательскими коллективами, лишь небольшое их число вышло на стадию реального клинического внедрения в медицинских организациях.
Одна из основных причин этого явления состоит в недостаточно высоком уровне доверия к ИИ-системам, которое в свою очередь подпитывается низким качеством отчетности об их создании и проверке, включая доклинические и клинические исследования.
Одним из основных способов снижения риска некачественной отчетности является соблюдение согласованных стандартов. Многие из них одобрены биомедицинскими журналами, описывают информацию, ожидаемую в статьях с результатами исследований и разработок, в том числе в ИИ-сфере. Как правило, они состоят из контрольного списка минимально необходимых пунктов, блок-схемы и сопровождаются более подробным документом, содержащим обоснование и образцы правильной отчетности.
Организация EQUATOR-NETWORK «Повышение качества и прозрачности исследований в области здравоохранения» (Enhancing the QUAlity and Transparency Of health Research»), обладает обширной библиотекой руководств по отчетности, среди которых можно выделить следующие стандарты:
- Рекомендации по интервенционным исследованиям (SPIRIT, https://www.equator-network.org/reporting-guidelines/spirit-2013-statement-defining-standard-protocol-items-for-clinical-trials),
- Объединенные стандарты отчетности по исследованиям (CONSORT, https://www.equator-network.org/reporting-guidelines/consort),
- Стандарты отчетности по диагностической точности (STARD, https://www.equator-network.org/reporting-guidelines/stard/),
- Прозрачное представление многопараметрической предиктивной модели для индивидуального прогноза или диагноза (TRIPOD, https://www.equator-network.org/reporting-guidelines/tripod-statement/).
В случае отсутствия стандарта для конкретного проекта исследования активно поощряется расширение существующих. В отсутствие стандартов, специфичных для ИИ, исследователи и читатели нередко сталкиваются с довольно типичными "подводными камнями", представленными в таблице 1.
| Этап | Распространенные «подводные камни» |
| Сбор данных | Многие исследования зависят от ранее собранных данных, которые часто предварительно маркируются для целей, отличных от разработки модели ИИ (например, для отчетов клинической радиологии или гистологии). Более того, при использовании открытых хранилищ данных, часто отсутствует информация о том, где, как и когда были собраны данные. Это серьезные подводные камни, учитывая, насколько важен контекст для оценки риска предвзятости и общей применимости |
| Разделение наборов данных | Разделение наборов данных часто бывает плохо разграничено. Модели ИИ, разработанные и протестированные с использованием перекрывающихся наборов данных, могут переоценить эффективность (например, способность модели ИИ диагностировать патологию) |
| Размер и распределение выборки | Тщательное определение размера набора данных, распределения и представления состояния индексов важно как для обучения, так и для тестирования. Производительность большинства моделей классификации может быть гарантирована только на распределениях и классах, адекватно представленных во время обучения модели |
| Критерии применения | Исключение данных как на уровне пациента, так и на уровне данных требует четкого указания в исследованиях. Отсутствие этой информации не позволяет изучить зависимость модели от конкретных параметров сбора данных (например, модель сканера, используемого для получения данных визуализации) |
| Доступность модели | Очень немногие исследования предоставляют подробную информацию о доступности модели ИИ или медицинского устройства, что исключает возможность независимой валидации и снижает в итоге доверие к работе |
| Объяснимость | Во многих исследованиях не делается попыток объяснить, как модель ИИ достигает своих результатов. Хотя это не всегда возможно, использование вспомогательных средств, таких как карты значимости (saliency maps), помогает добиться интерпретируемости и доверия конечного пользователя |
| Терминология | В терминологии по-прежнему нет единообразия. Например, "валидация" рассматривается сообществом компьютерных наук как процесс итеративного улучшения производительности модели с использованием обучающих и тестовых наборов данных. Однако биомедицинское сообщество рассматривает "валидацию" как единый процесс оценки производительности "закрытой" модели с использованием невидимого внешнего набора данных. Эти несоответствия могут привести к неоднозначному восприятию заинтересованными сторонами эффективности модели ИИ и общей клинической пользы |
| Выбор референтного стандарта | Этот процесс может включать выведение референтного стандарта из комбинации клинических, радиологических и лабораторных данных. Например, в рамках маммографических исследований использование результатов биопсии для классификации злокачественных и доброкачественных образований будет более точным эталоном, чем интерпретация маммограммы врачом. Однако, наоборот, получение биопсии из доброкачественных образований сопряжено с этическими и практическими проблемами. Поэтому выбор референтных стандартов требует тщательного планирования |
| Критерии оценки моделей | В настоящее время лишь немногие исследования сравнивают эффективность моделей ИИ с экспертами-клиницистами. Более того, в рамках оценки "in silico" многие исследования, как правило, не проводили валидацию своей модели на внешнем тестовом наборе; это плохая практика, которая, как было показано, приводит к завышенным показателям эффективности модели |
| Метрики качества моделей | В немногих диагностических исследованиях были представлены "традиционные" показатели результатов, такие как истинно положительные и ложно отрицательные результаты, в виде таблиц сопряженности. Когда использовались другие показатели, часто не приводилось обоснования, почему они были выбраны. |
Для того, чтобы устранить имеющиеся проблемы и повысить доверие к исследованиям и разработкам в сфере искусственного интеллекта для медицины и здравоохранения, в настоящее время проводятся работы по расширению следующих стандартов:
1. SPIRIT (Standard Protocol Items: Recommendations for Interventional Trials) 2013
2. CONSORT (Consolidated Standards of Reporting Trials) 2010
3. STARD (Standards for Reporting of Diagnostic Accuracy Studies) 2015
4. TRIPOD (Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis) 2015
Первое из руководств по отчетности направлено на повышения качества отчетности по протоколам клинических исследований (SPIRIT-AI, ссылка 1, ссылка 2), а также конечных результатов самих исследований (CONSORT-AI, ссылка 1, ссылка 2).
В совокупности эти документы призваны помочь читателям:
- понять предпосылки, обоснование, популяцию, методы, статистический анализ и этико-правовые аспекты
- помочь воспроизвести ключевые аспекты испытания (включая реализацию вмешательства)
- помочь в оценке научной достоверности исследования.
Чтобы достичь этих целей для медицинских исследований ИИ, SPIRIT-AI и CONSORT-AI содержат 15 и 14 новых пунктов, посвященных ИИ. Эти пункты сосредоточены вокруг 4 общих тем, посвященных вопросам, отмеченным в таблице 1: (1) модель ИИ, (2) набор данных, (3) инфраструктура и (4) прозрачность.
1. Модель ИИ.
Во-первых, необходимо предоставить подробную информацию о разработке и любой последующей валидации модели ИИ, поскольку об этом часто не сообщается в исследованиях по клинической валидации. Затем необходимо определить четкий сценарий использования в дополнение к информации о том, как модель будет вписываться в существующие клинические рабочие процессы и взаимодействовать с конечными пользователями. SPIRIT-AI и CONSORT-AI подчеркивают важность четких критериев того, кто (опыт и уровень квалификации) интерпретирует результаты, а также как интерпретировать результаты (например, диагностическую вероятность или классификацию) в контексте принятия клинического решения.
2. Набор данных.
Необходимо сообщить о критериях приемлемости как на уровне участников, так и на уровне данных. Разумно хранить их в виде отдельных пунктов. Например, должны быть четко сформулированы минимальные требования к вводу данных, которые могут быть связаны с разрешением изображения или форматом данных.
Кроме того, должны быть описаны четкие процедуры получения, отбора и предварительной обработки данных, чтобы обеспечить стандартизацию входных данных на разных исследовательских участках.
3. Инфраструктура.
Учитывая сложность предлагаемых систем ИИ, несколько пунктов посвящены описанию конкретных требований к программному и аппаратному обеспечению и обучению персонала, которые необходимы для внедрения вмешательства.
Эти требования можно разделить на требования на месте и вне места проведения исследования. И те, и другие крайне важно определить при оценке внедрения таких вмешательств.
4. Прозрачность.
Как SPIRIT-AI, так и CONSORT-AI подчеркивают, что прозрачность является важным моментом в процессе представления отчета об исследовании. Существуют пункты, призывающие указывать наличие и предполагаемое использование системы ИИ в названии или аннотации, что позволяет читателям однозначно понять предполагаемое использование ИИ-вмешательства.
Авторам рекомендуется указывать номер версии модели ИИ, связанной с исследованием, при этом любые изменения в ней требуют четкого обоснования. Существует рекомендация "описывать результаты любого анализа ошибок в работе и то, как были выявлены ошибки, если применимо".
Регулирующие органы отмечают, что о неблагоприятных инцидентах, возникающих в результате использования диагностического ИИ в качестве медицинского изделия, сообщается значительно меньше, и их трудно зафиксировать, поскольку значительная часть вреда для пользователей является косвенной. Наконец, есть пункты, связанные с тем, как можно получить доступ к модели ИИ и/или его коду, включая любые ограничения на доступ или повторное использование.
В дополнение к SPIRIT-AI и СONSORT-AI, дополнительные конкретные рекомендации, касающиеся отчетности по исследованиям диагностической точности и многовариантным прогностическим исследованиям, будут представлены в рамках инициатив STARD-AI и TRIPOD-AI и DECIDE-AI.
Эти инициативы обеспечат охват ИИ-специфическими руководствами по отчетности всего цикла исследований, начиная с составления протокола исследования и заканчивая представлением результатов испытаний различных методик. Эти инструменты окажут значительное влияние на качество и воспроизводимость исследований.
Инициатива TRIPOD (Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis), опубликованная в 2015 году, содержала минимальные рекомендации по представлению информации для исследований, по разработке или оценки эффективности прогностических моделей. TRIPOD 2015 в основном была посвящена регрессионным моделям. С момента публикации TRIPOD 2015 в области моделирования прогнозных моделей произошли многочисленные методологические изменения, особенно касающиеся используемых методов машинного обучения для создания моделей (например, случайные леса, глубокое обучение). С расширением доступа к данным и наличием готового программного обеспечения для применения методов машинного обучения разработка моделей прогнозирования стала быстрее и проще. В научной литературе появилось огромное количество моделей прогнозирования для многих клинических ситуаций, широкого спектра исходов и состояний здоровья, причем для одного и того же исхода, состояния здоровья и целевой популяции часто предлагается несколько моделей. Поэтому способность критически оценивать качество моделей прогнозирования и понимать их способность хорошо работать в конкретной ситуации или для конкретного сценария применения приобрело еще большую важность. Для растущего класса методов машинного обучения необходимы дополнительные требования к отчетности. Например, в отличие от моделей, основанных на регрессии, гибкость и сложность, лежащие в основе других алгоритмов машинного обучения, обычно означают, что итоговые модели прогнозирования не сводятся к простым уравнениям, а интерпретация влияния предикторов на прогноз затруднена. В связи с этим возникла необходимость обновить положения TRIPOD и в 2019 г. была объявлена, а в 2021 г. началась разработка TRIPOD-AI.
TRIPOD-AI представляет собой гармонизированное руководство по представлению отчетов об исследованиях моделей прогнозирования, независимо от того, использовались ли методы регрессионного моделирования или машинного обучения. Новый контрольный список заменил контрольный список TRIPOD 2015 года, который утратил актуальность. Цель TRIPOD-AI - гармонизировать ландшафт исследований моделей прогнозирования и способствовать полному, точному и прозрачному представлению результатов исследований, в которых разрабатывается предиктивная модель или оценивается ее эффективность. Полные отчеты облегчат оценку исследования, оценку модели и оценку потенциальной ценности ее внедрения. Для читателей (включая рецензентов, редакторов, медицинских работников, регулирующие органы, пациентов и широкую общественность) полная или точная отчетность повышает способность критически оценивать дизайн и методы исследования, быть уверенным в результатах. Полноценная отчетность о модели может также подсветить недостатки в дизайне исследования, сборе данных или проведении исследования.
Контрольный список TRIPOD-AI включает 27 основных пунктов, касающихся названия (пункт 1), аннотации (пункт 2), введения (пункты 3 и 4), методов (пункты 5-17), практики открытой науки (пункт 18), вовлечения пациентов и общественности (пункт 19), результатов (пункты 20-24) и обсуждения (пункты 25-27). Некоторые пункты включают несколько подпунктов, в общей сложности включены 52 подпункта контрольного списка. Любые пункты, обозначенные D и E, относятся ко всем исследованиям, независимо от того, касаются ли они разработки модели прогнозирования или оценки эффективности модели. Пункты контрольного перечня, обозначенные D, относятся к исследованиям, описывающим разработку модели прогнозирования, а пункты, обозначенные E, - к исследованиям, оценивающим эффективность модели. Для исследований, посвященных как разработке, так и оценке эффективности модели прогнозирования, применимы все пункты контрольного перечня TRIPOD-AI.
TRIPOD-AI не устанавливает структурированный формат и не диктует, в каком месте отчета или публикации должна находиться каждая отдельная рекомендация/подпункт, поскольку этот порядок может зависеть от редакционной политики и формата научного издания. Рекомендации, содержащиеся в TRIPOD-AI, являются минимальными, и авторы могут предоставлять дополнительную информацию. Если есть ограничения по объему текста рукописи и количеству таблиц и рисунков, которые затрудняют представление информации, авторы могут представить часть запрашиваемой или дополнительной информации в дополнительных материалах и сослаться на них. Если конкретный пункт контрольного списка не может быть рассмотрен в отчете из-за того, что информация неизвестна или неактуальна, то это должно быть явным образом указано. Дополнительные файлы и материалы исследования должны быть размещены в репозиториях общего назначения (например, Open Science Framework, Dryad, figshare) или в институциональных репозиториях открытого доступа, обеспечивающих бесплатный доступ к ним на бессрочной основе. Подробные сведения о доступе к любым дополнительным файлам должны быть указаны и связаны, например, с номером doi в основном отчете или публикации исследования. Шаблон контрольного списка TRIPOD-AI доступен для скачивания на сайте www.tripod-statement.org (контрольный список).
Основными пользователями и бенефициарами TRIPOD-AI станут исследователи, пишущие статьи, редакторы журналов и рецензенты, оценивающие научные работы, а также другие заинтересованные стороны (например, академические учреждения, разработчики политики внедрения ИИ, финансирующие организации, регулирующие органы, пациенты, участники исследований и широкая общественность), которые выиграют от повышения качества исследований моделей прогнозирования. Руководство актуально для любых отчетов, связанных с разработкой и валидацией клинических моделей прогнозирования, включая медицинские научные статьи и другие области, где требуются доказательные отчеты, например, для сопровождения программного обеспечения и инструментов.
DECIDE-AI - это новое руководство по составлению отчетов для ранней клинической оценки систем поддержки принятия решений на основе искусственного интеллекта (ИИ).
Все большее число систем поддержки принятия клинических решений на основе ИИ демонстрируют многообещающие результаты доклинической оценки in silico, но лишь немногие из них демонстрируют реальную пользу для лечения пациентов. Клиническая оценка на ранних стадиях важна для оценки реальной клинической эффективности системы ИИ, однако отчетность о таких ранних исследованиях остается недостаточной.
На ранних этапах клинической оценки систем ИИ следует уделять особое внимание проверке эффективности и безопасности, так как даже небольшие изменения в распределении исходных данных между популяциями обучающего алгоритма и клинической оценки (так называемый сдвиг набора данных) могут привести к значительным различиям в клинических показателях. Человеческие факторы, такие как оценка удобства использования, являются неотъемлемой частью процесса внедрения новых медицинских устройств, однако лишь немногие клинические исследования ИИ сообщают об оценке человеческих факторов, а оценка удобства использования соответствующих цифровых технологий здравоохранения часто проводится с непостоянством методологии и отчетности. Были отмечены и другие области неоптимальной отчетности клинических исследований ИИ, такие как среда реализации, характеристики пользователей и процесс отбора, обучение, описание базового алгоритма и раскрытие источников финансирования. Прозрачная отчетность необходима для оценки исследования и содействия воспроизводимости результатов исследования. В такой относительно новой и динамичной области, как клинический ИИ, всесторонняя отчетность также является ключевым фактором для создания общей и сопоставимой базы знаний, на которую можно опираться.
В экосистеме отчетности по ИИ протокол DECIDE-AI заполняет существующий пробел между исследованиями доклинической разработки и крупномасштабными итоговыми испытаниями. Рассматривая весь путь развития ИИ, TRIPOD-AI предоставляет руководство для отчетности о доклинической стадии разработки моделей прогнозирования. Валидация in silico и оценка в теневом режиме (тип оценки, при котором система ИИ используется в реальной клинической ситуации, но без влияния на нее) охвачены STARD-AI в отношении исследований точности диагностики. Затем, в мае 2022 г. появился протокол DECIDE-AI для исследований, направленных на первоначальное применение систем ИИ в небольших масштабах в реальных клинических условиях (т.е. когда поддерживаемые решения оказывают реальное влияние на лечение пациентов). Наконец, крупномасштабные, в идеале рандомизированные, контролируемые, исследования могут следовать руководству SPIRIT-AI для отчета о протоколе и CONSORT-AI для отчета о результатах (рисунок 1 и таблица 2).
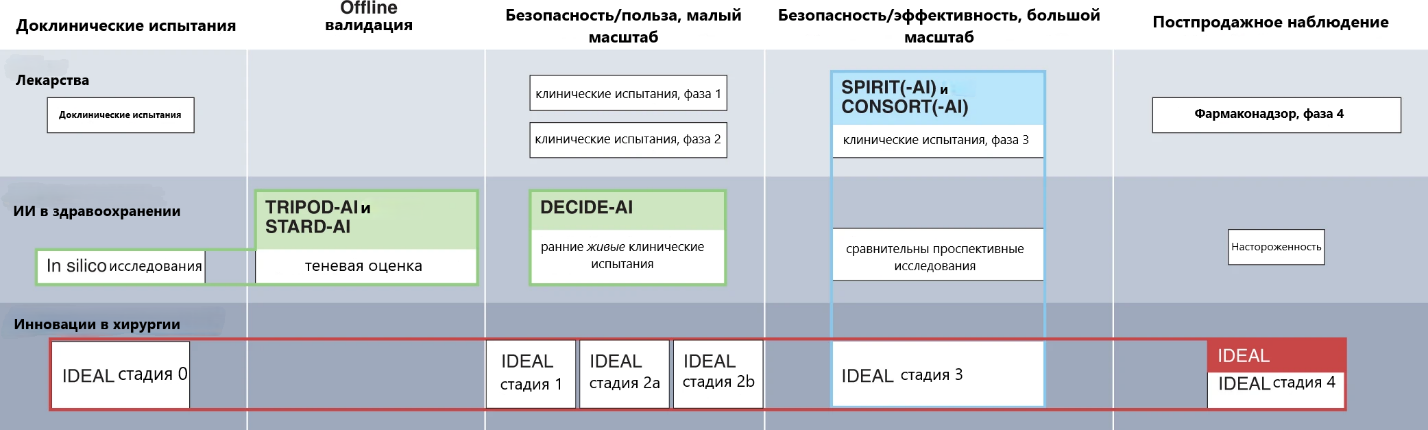
Рисунок 1. Сравнение путей разработки лекарственных препаратов, искусственного интеллекта в здравоохранении и хирургических инноваций.
Таблица 2. Обзор существующих и разрабатываемых руководящих принципов отчетности по ИИ.
| Руководства по составлению отчетов по искусственному интеллекту | |||
| Название | Стадия | Дизайн исследования | Комментарии |
| TRIPOD-AI | Доклиническая разработка | Оценка модели прогнозирования | Расширение TRIPOD. Используется для отчета о разработке, валидации и обновлении моделей прогнозирования (диагностических или прогностических). Основное внимание уделяется производительности модели. |
| STARD-AI | Доклиническая разработка и автономная валидация | Исследования точности диагностики | Расширение STARD. Используется для отчета об исследованиях диагностической точности, проводимых на стадии разработки или в качестве автономной валидации в клинических условиях. Фокусируется на точности диагностики. |
| DECIDE-AI | Ранняя клиническая оценка в реальном времени | Различные (проспективные когортные исследования, нерандомизированные контролируемые исследования, ...) с дополнительными возможностями, такими как модификация вмешательства, анализ заранее определенных подгрупп или анализ кривой обучения. | Самостоятельное руководство. Используется для ранней оценки систем искусственного интеллекта в качестве вмешательства в реальных клинических условиях (маломасштабная, формативная оценка), независимо от дизайна исследования и модальности системы искусственного интеллекта (диагностическая, прогностическая, терапевтическая). Основное внимание уделяется клинической полезности, безопасности и человеческим факторам. |
| SPIRIT-AI | Сравнительная проспективная оценка | Рандомизированные контролируемые исследования (протокол) | Расширение SPIRIT. Используется для составления протоколов рандомизированных контролируемых исследований, оценивающих системы искусственного интеллекта в качестве вмешательств. |
| CONSORT-AI | Сравнительная проспективная оценка | Сравнительная проспективная оценка | Расширение CONSORT. Используется для отчета о рандомизированных контролируемых исследованиях, оценивающих системы ИИ как вмешательства (крупномасштабная, суммарная оценка), независимо от модальности системы ИИ (диагностическая, прогностическая, терапевтическая). Фокусируется на эффективности и безопасности. |
В то время как TRIPOD-AI, STARD-AI, SPIRIT-AI и CONSORT-AI предназначены для конкретных дизайнов исследований, DECIDE-AI сфокусирован на этапе оценки и не предписывает фиксированный дизайн исследования. DECIDE-AI фокусируется на четырех основных аспектах ранней оценки: доказательство клинической полезности при использовании в реальных условиях в небольших масштабах, безопасность, оценка человеческих факторов и подготовка к последующим более масштабным испытаниям.
Оценке человеческих факторов уделяется особое внимание, так как надежная оценка человеческого фактора необходима в ходе клинических исследований как с научной, так и с производственной точки зрения. Акцент на роли принятия решений человеком обусловлен убежденностью создателей протокола в том, что ИИ, по крайней мере в обозримом будущем, будет скорее дополнять, чем заменять человеческий интеллект в клинических условиях. В этом контексте тщательная оценка взаимодействия человека и компьютера, и роли, которую играют люди-пользователи, будет иметь ключевое значение для реализации всего потенциала ИИ.
Вряд ли в ближайшем будущем медицинские работники будут слепо доверять результатам работы систем поддержки принятия решений на основе искусственного интеллекта при их использовании в реальных клинических условиях. Это будет особенно актуально до тех пор, пока врачи-люди будут нести ответственность за свои решения. Это означает, что, к лучшему или к худшему (данных по этому вопросу пока почти нет), врачи будут иногда игнорировать рекомендации систем ИИ и следовать собственным суждениям. Существование такого пробела в доверии имеет несколько последствий. Во-первых, он почти наверняка приведет к разнице между отдельной производительностью системы ИИ, оцененной в доклинических исследованиях, и производительностью комбинированной пары человек-ИИ, принимающей решения. Во-вторых, это делает характеристики пользователей неотъемлемой частью оценки, поскольку они становятся источником изменчивости и предвзятости. В-третьих, возникает вероятность непредвиденных ошибок и рисков для пациентов.
Сама по себе оценка на ранней стадии не даст сравнительных доказательств эффективности, для чего необходимы более масштабные испытания. Именно поэтому DECIDE-AI также включает в себя несколько пунктов, призванных помочь в подготовке последующих испытаний, поощряя предоставление информации, необходимой исследователям при разработке протоколов испытаний, например, потребности в обучении пользователей, ожидаемый размер эффекта от вмешательства или раннее вовлечение пациентов.
Руководство по отчетности DECIDE-AI включает 27 пунктов: 17 пунктов отчетности по специфике ИИ (состоящих из 28 подпунктов) и 10 общих пунктов отчетности. Каждый пункт сопровождается пояснением, почему и как рекомендуется представлять отчетность. Контрольный список следует рассматривать как минимальный стандарт научной отчетности, который не исключают представления дополнительной информации и не заменяют другие нормативные требования к отчетности.
DECIDE-AI следует использовать для представления отчетов об исследованиях, описывающих раннюю стадию клинической оценки систем поддержки принятия решений на основе ИИ, независимо от выбранного дизайна исследования. Руководящие принципы отчетности направлены на содействие прозрачному представлению исследований, а не на то, чтобы каждый аспект, охватываемый пунктом, обязательно оценивался в рамках исследования. Например, если оценка по какому-то пункту не была проведена, то для выполнения этого пункта достаточно указать, что она не была проведена, с сопутствующим обоснованием. Было также высказано мнение, что тщательная оценка систем ИИ не должна ограничиваться количеством слов и что в будущем к публикациям, посвященным таким исследованиям, могут быть предъявлены особые требования по формату. Информация, требуемая по нескольким пунктам, может быть уже представлена в предыдущих исследованиях или в протоколе исследования, и ее можно процитировать, а не описывать заново в полном объеме. Рекомендуется использовать ссылки, дополнительные материалы онлайн и репозитории открытого доступа (например, OSF).
Внедрение ИИ в здравоохранение должно быть подкреплено надежными, прочными и всеобъемлющими доказательствами и отчетами. Это необходимо как для обеспечения безопасности и эффективности систем ИИ, так и для завоевания доверия пациентов, практикующих врачей и покупателей, чтобы эта технология могла полностью реализовать свой потенциал для улучшения качества лечения пациентов. Руководство DECIDE-AI направлено на улучшение отчетности о клинической оценке систем искусственного интеллекта на ранних этапах, что закладывает основу для проведения более масштабных клинических исследований и последующего широкого внедрения. Руководство DECIDE-AI поможет авторам в разработке дизайна исследования, составлении протокола и регистрации исследования, предоставив им четкие критерии, на основе которых они смогут планировать свою работу.
Также отдельно для разработок систем ИИ в области медицинской визуализации в 2020 был предложен чек-лист CLAIM CLAIM был создан по образцу руководства STARD и расширен для учета особенностей применения ИИ в медицинской визуализации, включая классификацию и разметку изображений, построение изображений, анализ текста и оптимизацию рабочего процесса в лучевой диагностике.
Кроме этого был предложен универсальный IJMEDI чек-лист для детальной оценки процессов разработки и валидации медицинского ИИ вне зависимости от направления его применения в медицине.
Дополнительные гайдлайны, связанные с медицинским ИИ, представлены здесь: https://pubs.rsna.org/page/ai/blog/2022/09/ryai_editorsblog0928
Приведенные выше стандарты, гайдлайны и чек-листы во много пересекаются и конечный выбор при описании научного исследования в области медицинских ИИ технологий зависит от требуемой формы отчетности, а также требований научных изданий.
На более широком системном уровне данные стандарты, гайдлайны и чек-листы ставят перед собой цели максимизации (1) клинической и экономической эффективности проводимых исследований систем ИИ, (2) помощи регулирующим органам, врачам и ученым в процессах оценки и утверждения этих систем, а также, в конечном счете, (3) повышения качества, оказываемой помощи пациентам, опираясь на достоверные и воспроизводимые результаты исследований в области технологий искусственного интеллекта.
Публикация подготовлена с использованием материалов работы «Developing Specific Reporting Standards in Artificial Intelligence Centred Research», https://journals.lww.com/annalsofsurgery/Fulltext/2022/03000/Developing_Specific_Reporting_Standards_in.34.aspx, https://www.nature.com/articles/s41591-022-01772-9.