
Технологии искусственного интеллекта (ИИ) всё шире проникают в различные сферы жизни, меняя и ускоряя привычные процессы. Медицина не является исключением: с каждым годом в РФ внедряется всё больше медицинских изделий, использующих ИИ для различных задач – анализ карт пациентов, обработка медицинский изображений и т.д.
Сегодня проект Webiomed анализирует миллионы СЭМДов (структурированных электронных медицинских документов) с целью предиктивной аналитики для оценки рисков возникновения и развития различных заболеваний и нежелательных событий у пациентов.
Данные – это «топливо» для моделей машинного обучения. И качество данных напрямую влияет на качество получаемых моделей. Сложность обработки СЭМДов состоит в том, что легко интерпретируемые данные пациентов – такие как пол, возраст, регион проживания, результаты лабораторных анализов – это лишь «верхушка айсберга» ценной информации, которая содержится в электронных медицинских документах. Намного больше данных накоплено в неструктурированном текстовом виде.
Текстами разнообразного формата и содержимого наполнены протоколы осмотра, выписные эпикризы, инструментальные исследования и т.п. Извлечение из них данных в формате, однозначно интерпретируемом и машиночитаемом для последующего анализа моделями машинного обучения, - это задачи направления технологий искусственного интеллекта, которое называется NLP – Natural Languages Processing.
Сервис Webiomed.NLP работает с различными типами СЭМД и извлекает более 3х тысяч признаков различных типов: логических, числовых, категориальных и порядковых.
В одном документе может содержатся большое количество признаков разных типов. Например, протокол осмотра терапевтом, один из самых распространенных документов. В нём будут логические признаки: о вредных привычках, перенесенных заболеваниях, отягощённой наследственности, жалобах.
- Числовые: результаты измерения давления, роста, веса или записанные со слова пациента показатели глюкометра.
- Категориальные: стадия артериальной гипертензии.
- Комплексные: принимал ли пациент определенное лекарство, и, если да, то в какой дозировке и как долго.
В осмотрах врачей разных специальностей, каждом типе инструментального исследования в текстовом виде содержится множество признаков, которые после извлечения можно использовать как шкалах оценки рисков заболеваний, так и в моделях, построенных с помощью машинного обучения (ML).
Модели ML могут работать с текстами и без этапа извлечения конкретных признаков – для этого тексты перед использованием моделью проходят векторизацию – но это делает механизм оценки рисков заболеваний сложно интерпретируемым и, чаще всего, менее точным.
Самый простой способ извлечь логические признаки из текста в формате False/True – это искать их упоминания в тексте, и при его наличии давать признаку значение True. Но для медицинских данных этого подхода будет недостаточно. Например, упоминание курения. При анализе важно отличить, подтверждает или опровергает пациент факт курения. Или при опросе не отвечает на этот вопрос вовсе, что тоже нельзя интерпретировать как «нет». Или речь в документе о ребенке, а упоминается курение одного из его родителей. Нюансы обработки и интерпретации некоторых признаков ставят перед исследователями задачу искать различные подходы к их извлечению в зависимости от контекста задачи и медицинской ситуации, составления записи.
Основная сложность обработки неструктурированных записей из СЭМДов состоит в высоком разнообразии структуры текстов, в зависимости от МИС или заполняющего их медицинского работника, наличие специфических терминов, сокращений, опечаток. В том же самом примере с курением, одна и та же информация, что человек не курит, может быть записана множеством способов: «не курит», «курение отрицает», «табакокурение отрицает», «курение отр.», «крение отр.», «курение, алкоголизм, употребление запрещенных веществ отрицает».
Также во многих медицинских организациях используются «шаблоны», например, для заполнения данных объективного осмотра, которые помогают врачу, работающему в условиях ограниченного времени, отразить все важные характеристики пациента. Но в реальности, шаблон, используемый врачом, может попасть в БД в незаполненном виде, из-за чего в записях у одного пациента тоны сердца будут одновременно «ясные, приглушены, глухие, ритмичные, аритмичные», а язык «влажный, чистый, сухой». Кроме того, количественные признаки могут быть введены с ошибками в цифрах, из-за чего у пациента может обнаружиться пульс 600. Из-за этого извлечение и последующее использование данных «вслепую», без использования форматно-логического контроля результата негативно скажется на качестве моделей, которые строятся на их основе.
Разумеется, сегодня разработчикам и исследователям не нужно перечислять вручную все варианты написания признака, чтобы извлечь его корректно. Развитие технологий создания NLP моделей позволяет решать задачи извлечения из текстовых данных быстрее и эффективнее. Однако, NLP модели, обученные на «общих» текстовых данных, справляются с задачей извлечения данных из неструктурированных медицинских текстов с низким качеством, что ставит необходимость разработки специализированных, предварительно обученных моделей [Benyou Wang & Xie, Qianqian & Pei, Jiahuan & Chen, Zhihong & Tiwari, Prayag & Li, Zhao & Fu, Jie. (2023). Pre-trained Language Models in Biomedical Domain: A Systematic Survey. ACM Computing Surveys. 56. 10.1145/3611651].
В сервис Webiomed.NLP включены множество NLP моделей, построенных на различных технологиях, в зависимости от решаемой задачи. В этой статье мы расскажем о некоторых из них.
Подход, основанный на правилах (Rule-based approach)
Наиболее простой и понятный подход, в основе которого лежат составленные с привлечением медицинского эксперта правила – например, в форме регулярных выражений. Подходит для извлечения признаков с низкой вариативностью, как, например, названия лекарственных средств.
Пример использования:
«Эуфиллин 2,4%- 5,0 в/в №3, Дексаметазон 8 мг в/в №3, физиолечение»

У этого подхода есть свои преимущества: скорость работы, легкая интерпретация и редактирование правил извлечения. Однако, создание универсальных правил для сложных признаков, обладающих высокой степенью вариативности, будет очень трудоемко. Поэтому многие исследователи используют достижения в области ИИ для обработки медицинских данных
Подход, основанный на обучении моделей на больших наборах размеченных данных
При этом подходе размеченные медицинскими экспертами наборы данных используются для обучения NLP-моделей c использованием технологий машинного обучения. Подобный подход к созданию моделей носит название «обучение с учителем». Обучение NLP-модели на разнообразной выборке позволяет извлекать признаки с высокой вариативностью написания. В зависимости от задач, в Webiomed используются различные алгоритмы: градиентный бустинг (Gradient Boosting), условные случайные поля (Conditional random fields), сверточные нейронные сети (Convolutional neural network) и т.д. Методы предварительной обработки и векторизации данных зависят как от используемого алгоритма обучения, так и от специфики данных.
Пример работы модели, обученной на экспертных данных:
«Жалобы на мелькание мушек перед глазами»

Преимуществом этого подходы является возможность учета высокой вариативности описания искомого признака. Недостатками является сложность интерпретации и внесения изменений – для разработчика модель является «черным ящиком», – а также необходимость разметки экспертами больших объемов выборки документов.
Подход, основанный на создании экспертами инструкций и использовании эмбеддингов, построенных на неразмеченной выборке
Эмбеддинги (Word Embedding) – подходы к моделированию языка и векторизации текстов для дальнейшего использования в различных задачах анализа. Использование эмбеддингов позволяет объединить возможности нейронных сетей и человеческой экспертизы, сохраняя время экспертов благодаря моделированию естественного языка, и делает возможных извлечение более сложных, контекстно-зависимых признаков.
Эмбеддинги позволяют не только представлять словарь в виде вектора, по размеру меньшем, чем количество уникальных слов в выборке, но и совершать над ними математические преобразования. Например, между векторами слов, созданными с помощью эмбеддингов, можно вычислить косинусное расстояние (разницу), которое будет мерой их семантической близости. Семантическая близость измеряется в диапазоне от 0 до 1, где 1 - полное совпадение, и 0 – наиболее далекий вектор. Семантическая близость между словами в модели эмбеддингов будет тем выше, чем чаще они употреблялись в одном контексте. То есть между словами (словосочетаниями), находящимися в высокой степени семантической близости существуют какие-либо семантические отношения - синонимия, гипонимия, ассоциативность, когипонимия. Примеры близости слов в модели, обученной на медицинских данных, используемой в Webiomed:

Из этого примера видно, что слова «кисть» и «рука» с большей вероятностью состоят в семантических отношениях, чем «рука» и «желудок».
Существуют различные подходы к созданию моделей эмбеддингов, одной из первых, получивших распространение, была модель Word2Vec [Mikolov, Tomas; et al. (2013). "Efficient Estimation of Word Representations in Vector Space". arXiv:1301.3781]. Но с момента публикации модели Word2Vec, которая на тот момент стала революцией в области обработки естественного языка, появился ряд других моделей эмбеддингов, которые более успешно справляются с частными задачами обработки. Например, эмбеддинги на основе Fasttext хорошо подходят для предметно-специфичных текстов с ограниченной обучающей выборкой, что было доказано на задачах анализа медицинской литературы и публикаций [Agibetov, A., Blagec, K., Xu, H. et al. Fast and scalable neural embedding models for biomedical sentence classification. BMC Bioinformatics 19, 541 (2018). https://doi.org/10.1186/s12859-018-2496-4].
В открытом доступе доступны также большие «универсальные» языковые модели, обученные на общедоменных данных. Но как подчеркивают исследователи в своих работах «общие» модели не подходят для обработки биомедицинских данных [Сhiu, Billy & Baker, Simon. (2020). Word embeddings for biomedical natural language processing: A survey. Language and Linguistics Compass. 14. 10.1111/lnc3.12402].
Наиболее подходящая для обработки биомедицинских данных модель эмбеддингов – всё ещё дискуссионный вопрос. Алгоритм обучения, размеры выборки, способы её предварительной предобработки зависят от качества доступных данных и поставленной задачи обработки.
В последнее время активно исследуются модели на основе трансформеров. Кроме известной модели для генерации, ChatGPT, на основе трансформеров построена модель BERT, которая может использоваться в том числе для получения эмбеддингов и вычисления семантических связей между словами. Модель BERT лучше, чем Word2Vec и Fasttext работает с контекстом и синтаксическими конструкциями. Также перспективным является использование алгоритма Bi-LSTM для работы с контекстными признаками и языковой многозначностью [Sun, Y., Platoš, J. A method for constructing word sense embeddings based on word sense induction. Sci Rep 13, 12945 (2023). https://doi.org/10.1038/s41598-023-40062-3].
В рамках анализа текстов медицинских документов эмбеддинги позволяют не только находить близкие контекстные синонимы терминов, но и корректно распознавать ошибочные написания терминов, опираясь не только на совпадение символов, но и общий контекст употребления. Проблема интерпретации различных сокращений, альтернативных и ошибочных написаний терминов очень актуальна для анализа медицинских документов. Визуализация семантической близости ошибочных написаний слова «температура» представлена на рис. 1.
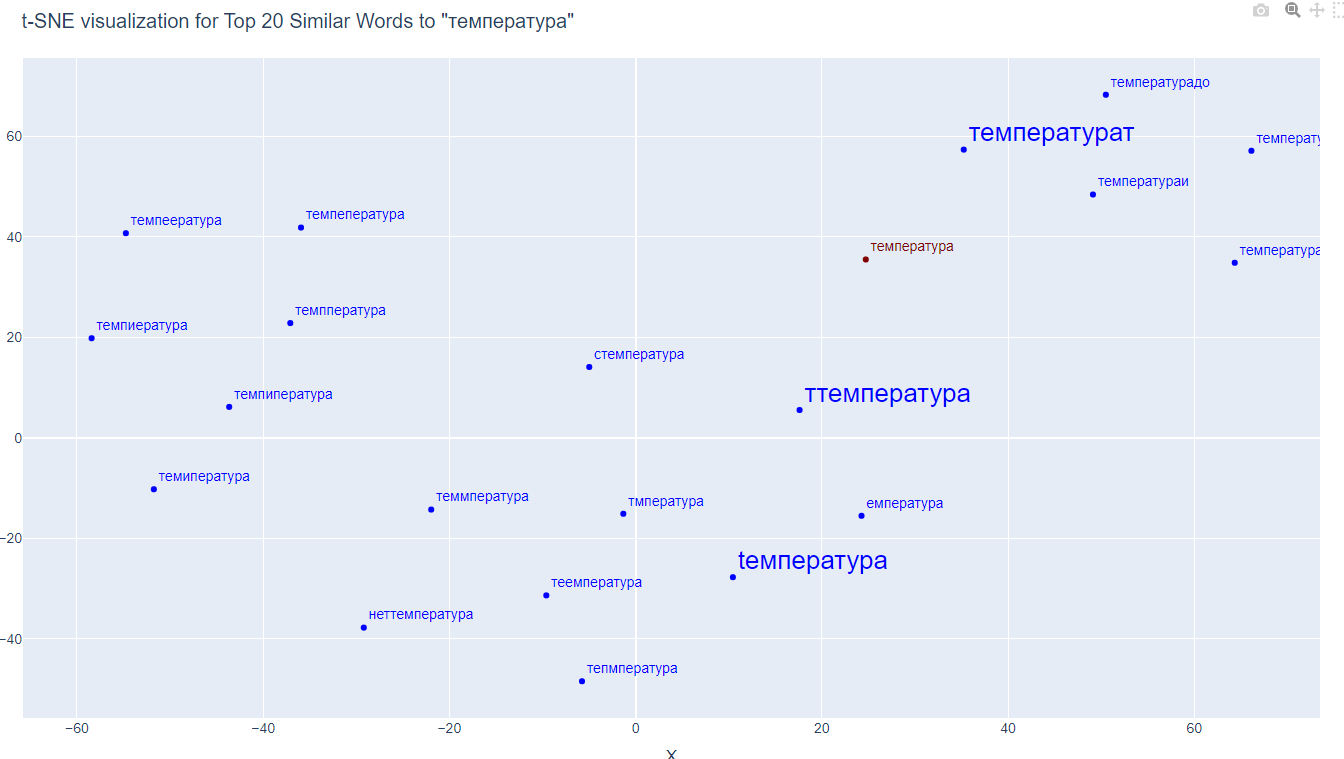
Рис. 1.
Визуализация построена на основе модели эмбеддингов, которая используется в Webiomed для решения ряда задач извлечения признаков. Модель обучена на 2,7 млн. документах из реальной клинической практики. Представленные слова имеют высокую семантическую близость не только по причине наличия общих символов, но и по причине частой встречаемости в одном контексте. Например, поэтому, слово «беременность» будет иметь намного большую семантическую близость со своим вариантом сокращения «бр-сть», чем со словом «бренность», в котором больше общих символов, но нет общего контекста употребления.
Пример работы модели на основе эмбеддингов представлен ниже:
«Не курит. Алкогольная зависмость. ОМНК, ЧМП отрицает»
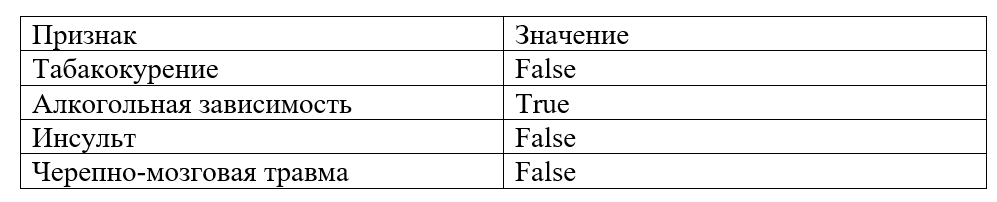
Преимуществом использования моделей эмбеддингов является возможность создавать их на большом объеме данных без разметки экспертом, в режиме «обучения без учителя», что позволяет сократить ценное время медицинских экспертов, участвующих в создании инструкций для извлечения признаков. В платформе Webiomed модели на основе эмбеддингов используются как для извлечения логических, так и для категориальных или числовых значений.
Валидация в Webiomed.NLP
После разработки, каждый признак в платформе Webiomed проходит тщательную валидацию на выборке из реальной клинической практики. При создании выборки обеспечивается разнообразие текстов по:
- источникам документов
- пациентам
- используемой лексике
Выборки размечаются медицинскими экспертами с консенсусом не менее 2х человек по спорным вопросам. После разметки, результаты экспертной оценки сравниваются с результатами работы NLP-сервиса.
Для логических признаков используется метрика F1-score:
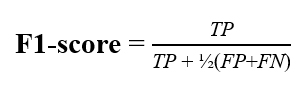
Где TP — true positive (истинно-положительные), TN — true negative (истинно-отрицательные), FP — false positive (ложно-положительные), FN — false negative (ложно-отрицательные) результаты работы сервиса. «Золотым стандартом» при разработке NLP признаков в Webiomed считается достижение F1-score не менее 0.9 при валидации на разнообразной выборке документов из разных медицинских организаций.
Для оценки точности извлечения числовых признаков используется метрика RMSE:
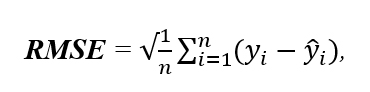
где y_i – значение, выделенное экспертом, y ̂_i- значение, полученное NLP-моделью. Это позволяет избегать различных ошибок извлечения числовых признаков, как, например, извлечение даты анализа вместо его результата.
После успешного прохождения валидации, модели для извлечения признаков встраиваются в платформу Webiomed и дополняются по мере необходимости. Валидация признаков также проводится повторно при обновлении используемых моделей, чтобы не терять качества извлечения.
В зависимости от решаемой задачи, в Webiomed используют различные подходы к извлечению признаков, комбинируя их. В планах команды продолжать расширять список извлекаемых признаков и проводить исследования для улучшения достигнутых показателей точности и определения наилучших подходов для анализа медицинских данных.
Авторы : Анна Андрейченко (руководитель направления ИИ) и Елена Макарова (аналитик данных направления NLP)