
Введение
Искусственный интеллект (ИИ) представляет собой динамично развивающееся направление, которое уверенно проникает во все отрасли, включая здравоохранение.
Практически ни одна конференция или проект, связанный с цифровым здравоохранением, не обходятся без упоминания ИИ. Мы повсеместно слышим о машинном обучении, предиктивной аналитике, чат-ботах, компьютерном зрении, обработке естественного языка. А в последнее время стали популярными еще и такие термины, как генеративный ИИ, большие языковые модели и т.д.
При этом одной из проблем является то, что все эти термины, находясь в обиходе, порой понимаются и используются довольно небрежно – что может приводить как к взаимному непониманию, так и просто к неграмотному употреблению. Эта проблема затрудняет качественное и объективное представление результатов проводимых исследований и разработок, описание ИИ-решений и связанных с ними проектов разным аудиториям, а также эффективную коммуникацию между заинтересованными лицами.
Необходимость решения данной проблемы давно созрела и заключается в определении и использовании единой терминологии.
На основе различных источников, нашего опыта и знаний мы систематизировали и сформировали краткий глоссарий, включающий в себя понятия, используемые при разработке платформы Webiomed на основе технологий искусственного интеллекта.
Ключевые понятия в сфере искусственного интеллекта
Искусственный интеллект (Artificial intelligence, AI) комплекс технологических решений, позволяющий имитировать когнитивные функции человека (включая поиск решений без заранее заданного алгоритма) и получать при выполнении конкретных задач результаты, сопоставимые с результатами интеллектуальной деятельности человека или превосходящие их ( Указ Президента РФ от 10.10.2019 N 490 (ред. от 15.02.2024) "О развитии искусственного интеллекта в Российской Федерации" (вместе с "Национальной стратегией развития искусственного интеллекта на период до 2030 года").
Достаточно часто под термином искусственный интеллект понимается широкая область знаний, которая опирается на исследования разных наук (компьютерных наук, статистики, экономики, нейробиологии, лингвистики, психологии и философии), каждая из которых имеет свой понятийный аппарат, предметную область исследований и методологическую базу.
Машинное обучение (Machine Learning, ML) — процесс автоматического обучения и совершенствования поведения системы искусственного интеллекта на основе обработки массива обучающих данных без явного программирования [ГОСТ Р 59895-2021, статья 2.1.7]
Машинное обучение является базовой технологией ИИ, позволяющей создавать программные модели, которые на основе данных помогают компьютеру обучаться без непосредственных инструкций со стороны человека (ПРИМЕНЕНИЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА НА ФИНАНСОВОМ РЫНКЕ. Доклад для общественных консультаций. Центральный банк Российской Федерации, 2023).
Машинное обучение можно классифицировать на два больших раздела:
- Классическое машинное обучение (Classic Machine Learning, Classic ML), основанное на «неглубоких» алгоритмах и методах математической статистики.
- Глубокое обучение (Deep Learning, DL), основанное на архитектурах и технологии искусственных нейронных сетей.
Бытует мнение, что одни из самых продвинутых и точных моделей машинного обучения для применения в задачах здравоохранения создаются с использованием глубокого обучения. Но на самом деле это не так. Среди научных исследований и практических разработках существует множество примеров, когда с помощью обычного классического машинного обучения были созданы эффективные и точные решения. При этом они обладает более высокой объяснимостью и меньшими требованиями ко времени обучения и объемам наборов данных.
Набор данных (dataset) - состав данных, которые структурированы или сгруппированы по определенным признакам, соответствуют требованиям законодательства и необходимы для разработки программ для электронных вычислительных машин на основе искусственного интеллекта.
Довольно часто в качестве источника для создания наборов данных для машинного обучения используют данные реальной клинической практики – электронные медицинские карты (ЭМК), результаты радиологических исследований в формате DICOM и т.д.
Данные реальной клинической практики, RWD (real-world data, RWD) - информация о состоянии здоровья пациентов и/или об оказании медицинской помощи, полученная из различных источников вне рамок предрегистрационных клинических исследований. [ГОСТ Р 59921.3—2021, пункт 3.2]
Базовые термины в области машинного обучения
- Алгоритмы машинного обучения (Machine Learning Algorithms) —математические методы моделирования, используемые для изучения или выявления внутренних закономерностей и правил, заложенных в данных.
- Метод машинного обучения (Machine Learning Methods) – это конкретный метод тренировки алгоритма машинного обучения, зависящий от наличия или отсутствия разметки данных.
- Модель машинного обучения (Machine learning model) — представление алгоритма или ансамбля алгоритмов машинного обучения с фиксированными весами, полученными в результате его обучения.
- Большие фундаментальные модели (Foundation models) — модели искусственного интеллекта, являющиеся основой для создания и доработки различных видов программного обеспечения, обученные распознаванию определенных видов закономерностей, содержащие не менее 1 млрд. параметров и применяемые для выполнения большого количества различных задач.
- Большие генеративные модели (Generative models)— модели искусственного интеллекта, способные интерпретировать (предоставлять информацию на основании запросов, например об объектах на изображении или о проанализированном тексте) и создавать мультимодальные данные (тексты, изображения, видеоматериалы и тому подобное) на уровне, сопоставимом с результатами интеллектуальной деятельности человека или превосходящем их.
- Упакованная модель машинного обучения (ML model packaging) – совокупность самой модели машинного обучения, блока проверки входных признаков для модели и выходных данных модели, а также блока обработки признаков и формирования расчетных признаков, объединенных единым программным кодом.
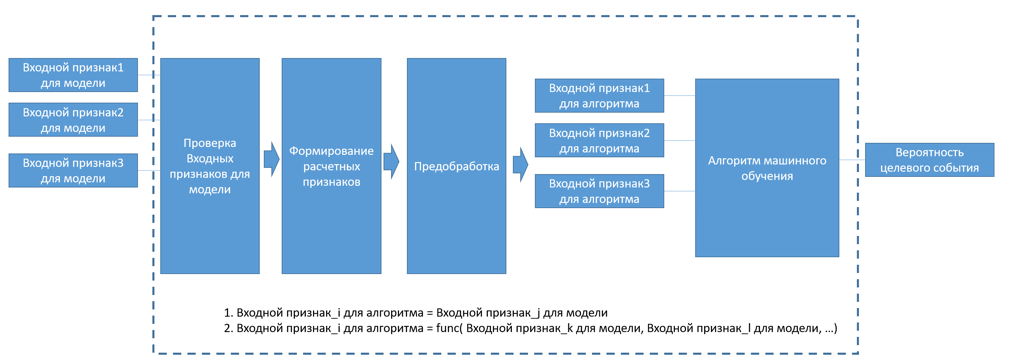
Рисунок 1. Блок-схема упакованной модели машинного обучения.
Термин «Признаки» и связанные с ними определения
Для создания моделей машинного обучения необходимы данные в виде значений признаков, представляющие собой примеры решений, статистики, расчеты, показатели или исторические события, а также алгоритмы машинного обучения в качестве инструментов самого обучения.
- Признак (features) — достаточное условие для принадлежности объекта некоторому классу. В менее строгих науках слово «признак» употребляется, как описание фактов, позволяющих (согласно существующей теории и тому подобное) сделать вывод о наличии интересующего явления» (https://ru.wikipedia.org/wiki/Признак)
- Входные признаки для модели (input data) — это данные, которые подаются на вход упакованной модели. Входные признаки для модели могут состоят из входных признаков для алгоритма и дополнительных признаков, из которых формируются входные признаки для алгоритма.
- Расчетные признаки — это входные признаки для алгоритма, значения которых формируются внутри упакованной модели на основе входных данных.
- Обязательные признаки — это перечень входных признаков, наличие значений которых обязательно для построения прогноза с помощью упакованной модели.
Номенклатура машинного обучения в сравнении с традиционным статистическим моделированием:
| Термин машинного обучения | Статистический концепт |
| Параметр/признак/показатель/ индикатор/предиктор (feature) |
Независимая переменная (independent/explanatory variable) |
| Отклик/результирующая переменная/результат (label/response/outcome) |
Зависимая/результирующая переменная (dependent variable) |
| Выбор параметров (feature selection) |
Выделенные/вторичные признаки (extracted features) |
| Выбор переменных (variable selection) |
Латентная/преобразованная переменная (latent or transformed variables) |
| Настройка/оптимизация модели (model optimization) |
Подгонка/подбор модели (model fitting) |
| Веса (weights) | Параметры (parameters) |
| Полнота (recall) Чувствительность (sensitivity) | Точность (precision) Положительная прогностическая ценность (positive predictive value) |
Термины в области алгоритмов классического машинного обучения
- Ансамбль алгоритмов (Ensemble learning) — подход, который использует несколько алгоритмов машинного обучения с целью получения лучшей эффективности прогнозирования, чем можно было бы получить от каждого алгоритма по отдельности (http://neerc.ifmo.ru/wiki/index.php)
- Бустинг (Boosting) — метод построения ансамбля однородных алгоритмов, в котором каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов.
- Бэггинг (Bagging)— метод построения ансамбля однородных алгоритмов, в котором обучение базовых алгоритмов производится параллельно на отдельной выборке, сформированной из исходного набора данных с помощью бутстрэпинга.
- Cтекинг (Stacking) — метод построения ансамбля, в котором происходит обучение нескольких разнородных алгоритмов на исходных данных и передача их результатов на вход последнему, который называют мета-алгоритмом.
Термины в области прогнозной аналитики
- Прогнозная аналитика в сфере здравоохранения (predictive analytics in healthcare) - комплекс технологических решений, позволяющий анализировать данные для получения прогнозов состояний здоровья пациентов или показателей, используемых при планировании и управлении системой здравоохранения.
- Система прогнозной аналитики в сфере здравоохранения на основе искусственного интеллекта (predictive analytics system in healthcare based on artificial intelligence) - программное обеспечение, позволяющее внедрить и применять автоматизированное получение прогнозной аналитики в сфере здравоохранения с использованием технологий искусственного интеллекта.
- Модель прогнозирования - описание объекта прогнозирования, последовательность и правила выполнения действий для достижения цели, в том числе логико-лингвистических моделей и вычислительных операций в системах прогнозной аналитики в сфере здравоохранения на основе искусственного интеллекта.
Термины в области систем поддержки принятия решений
- Система поддержки принятия врачебных решений (СППВР, Clinical decision support system, CDSS) - программное обеспечение, позволяющее путем интерпретации собираемой информации поддерживать принятие врачом решения на всех этапах лечебно-диагностического процесса с целью снижения ошибок и повышения качества оказываемой медицинской помощи.
- Алгоритм системы поддержки принятия врачебных решений (алгоритм СППВР) - последовательность и правила выполнения действий, применение логико-лингвистических моделей, проведение вычислительных операций в системе поддержки принятия врачебных решений.