
Альберт Эйнштейн: «Если вы не можете объяснить что-то простым языком, вы этого не понимаете».
Зачем нужно объяснимое машинное обучение
Модели машинного обучения считаются «черными ящиками». Это не означает, что мы не можем получить от них точный прогноз, мы не можем понятно объяснить или понять логику их работы.
Четкое математическое определение интерпретируемости в машинном обучении отсутствует. Есть несколько определений:
• Интерпретируемость - это степень, в которой человек может понять причину решения (Миллер (2017)).
• Интерпретируемость - это степень, в которой человек может последовательно предсказывать результат модели. Чем выше интерпретируемость модели машинного обучения, тем легче кому-то понять, почему были приняты определенные решения или прогнозы. Модель лучше интерпретируется, чем другая модель, если ее решения легче понять человеку, чем решения другой модели.
• Интерпретируемость - это способность объяснить ее действие или показать его в понятном человеку виде.
Модель оказывает определенное влияние на последующие принятия решений, например, в системах поддержки принятия врачебных решений (СППВР). Очевидно, что интерпретируемость для СППВР будет гораздо важнее, чем для тех моделей, которые используются для прогнозирования результата классификации вин.
«Проблема заключается в том, что всего одна метрика, такая как точность классификации, является недостаточным описанием большинства реальных задач.» (Доши-Велес и Ким) 2017.
Для понимания и интерпретация работы модели нам потребуются:
- Определить наиболее важные признаки (feature importance) в модели.
- Для конкретного прогноза модели влияние каждого отдельного признака на конкретный прогноз.
- Влияние каждого признака на большое количество возможных прогнозов.
Рассмотрим несколько методов, которые помогают извлекать вышеперечисленные особенности из модели.
Permutation Importance
Какие признаки модель считает важными? Какие признаки оказывают наибольшее влияние? Эта концепция называется важностью признаков (feature importance), а Permutation Importance – это метод, широко используемый для вычисления важности признаков. Он помогает нам увидеть, в какой момент модель выдает неожиданные результаты или работает корректно.
Permutation importance отличается:
- Его быстро посчитать;
- Широко применяется и легко понимается;
- Используется вместе с метриками, которые обычно используются.
Допустим, у нас есть датасет. Мы хотим предсказать рост человека в 18 лет, используя данные, которые о нем имеются в 12 лет. Проведя случайное переупорядочивание одного столбца, получим выходные прогнозы менее точными, так как полученные данные больше не соответствуют чему-либо в нашем датасете.
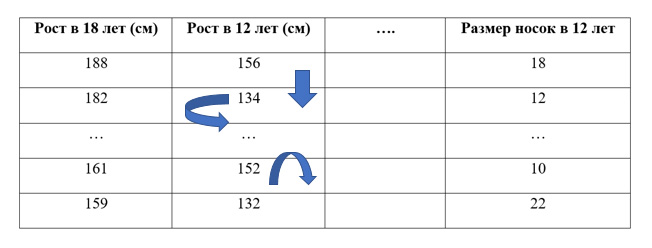
Точность модели особенно страдает, если мы перемешиваем столбец, на который модель сильно опиралась для прогнозов. В этом случае перетасовка «роста в 12 лет» вызвала бы непредсказуемые прогнозы. Если бы вместо этого, мы перетасовали «размер носок», то предсказания не пострадали бы так сильно.
Процесс выявления важности признаков выглядит следующим образом:
- Получаем обученную модель на «нормальных» данных, вычисляем для нее метрики, в том числе и значение функции потерь.
- Переставляем значения в одном столбце, прогнозируем с использованием полученного набора данных. Используем эти прогнозы и истинные целевые значения, чтобы вычислить, насколько функция потерь ухудшилась от перетасовки. Это ухудшение производительности измеряет важность переменной, которую только что перемешали.
- Возвращаем данные к исходным значениям и повторяем шаг 2 со следующим столбцом в наборе данных, пока вычисляется важность каждого столбца.
Для вычисления permutation importance есть несколько готовых библиотек, рассмотрим примеры работы с ними.
Библиотека SkLearn
SkLearn - самый распространенный выбор для решения задач классического машинного обучения. Классы в модуле sklearn.feature_selection (https://scikit-learn.org/stable/modules/feature_selection.html#rfe) могут использоваться для выбора признаков / уменьшения размерности на выборочных наборах, либо для улучшения показателей точности оценщиков, либо для повышения их производительности на очень многомерных наборах данных.
Так, библиотека sklearn и метод рекурсивного отбора признаков , были использованы в модели прогнозирования возникновения ампутации нижних конечностей у пациентов с сахарным диабетом 2 типа в течение 5 лет. Изначально были использованы 99 возможных признаков объективных и лабораторных данных пациентов с сахарным диабетом 2 типа. С помощью этого метода оценивалось различное количество N признаков и их влияние на точность предсказания. В итоге были выбраны только 20 признаков (триглицериды, прием препаратов: периферические альфа-адреноблокаторы, сульфонилмочевины, ингибиторы альфа-глюкозидазы, ингибиторы абсорбции холестерина, пероральные антикоагулянты, повышение микро или макроальбуминурия в течение последних 2 лет, ГЛЖ по ЭКГ или эхокардиограмме за последние 2 года, табакокурение, наличие ретинопатии), при которых модель достигает наибольшей точности AUC =0.809.
Библиотека ELI5
ELI5 – это библиотека в Python, которая позволяет визуализировать различные модели машинного обучения с помощью унифицированного API (https://github.com/TeamHG-Memex/eli5). Имеет встроенную поддержку для нескольких ML-фреймворков и обеспечивает способы интерпретации модели черного ящика.
Рассмотрим модель, которая предсказывает как играет футбольная команда и сможет ли она пол награду “Man of the Game” или нет, на основе определенных параметров.
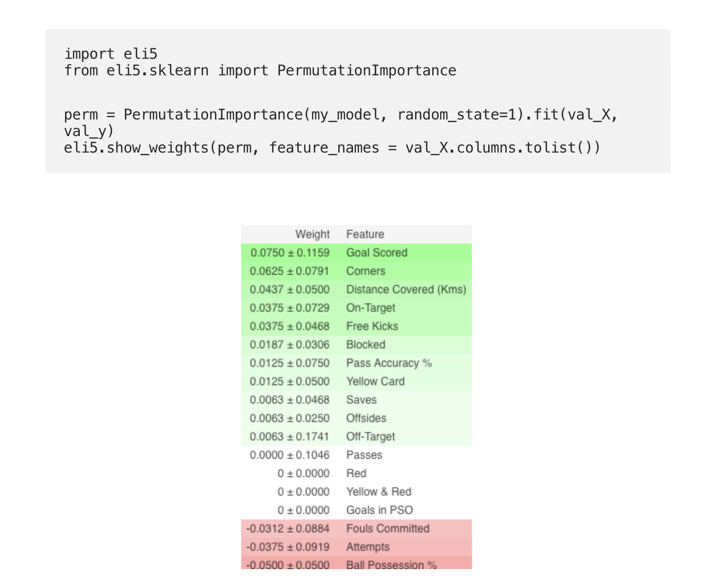
(Здесь val_X,val_y обозначают соответственно наборы валидации)
Визуализаторы используются для обнаружения функций или целей, которые могут повлиять на последующую подгонку.
В следующем примере рассматриваются функции Rank1D и Rank2D для оценки отдельных функций и пар функций с помощью различных показателей, которые оценивают функции по шкале [-1, 1] или [0, 1].
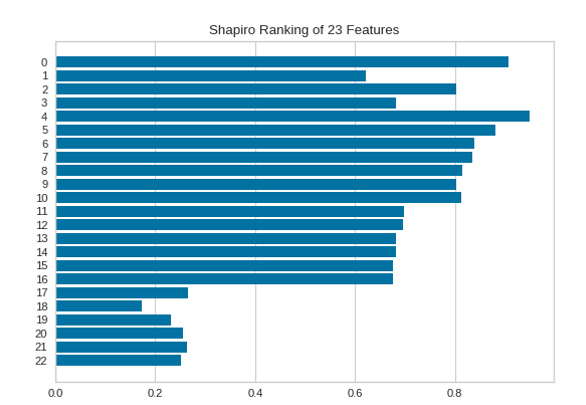
При одномерном ранжировании функций [Rank1D] используется алгоритм ранжирования, который учитывает только одну функцию за 1 раз.

Значимость каждого из 23 признаков отображена на следующем рисунке, чем больше значение, тем важнее признак.
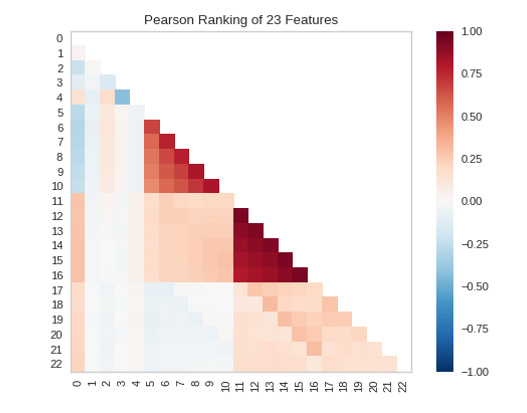
При двумерном ранжировании функций [Rank 2D] используется алгоритм ранжирования, который одновременно учитывает пары функций. Для этого удобно использовать корреляцию по Пирсону, которая показывает связь двух признаков между собой. Чем больше число, тем сильнее коррелированы признаки.
Partial Dependence Plots – PDP
График частичной зависимости (PDP или график PD) показывает краевой эффект одного или двух признаков на прогнозируемый результат модели машинного обучения (J. H. Friedman 2001). График частичной зависимости может показать, является ли отношение между целью и признаком линейным, монотонным или более сложным. Например, при применении к модели линейной регрессии графики частичной зависимости всегда показывают линейную зависимость.
Для классификации, где модель машинного обучения выводит вероятности, график частичной зависимости отображает вероятность для определенного класса, заданного различными значениями для признаков. Простым способом для отображения с несколькими классами, является рисование одной линии или графика для каждого класса. График частичной зависимости является глобальным методом: Метод рассматривает все экземпляры и даёт утверждение о глобальной взаимосвязи признака с предсказанным результатом.
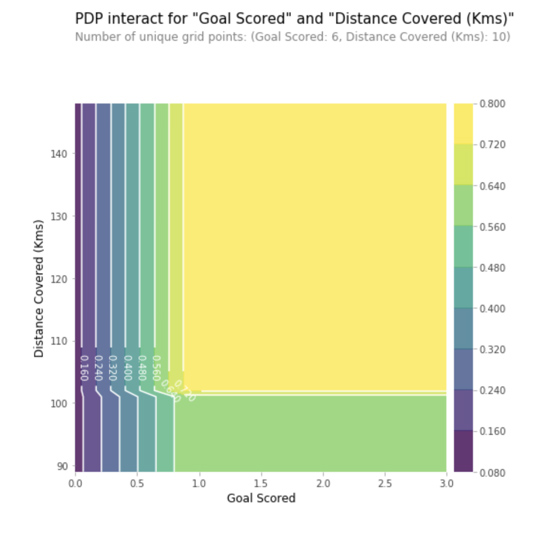
На данном графике Ось Y отражает изменение прогноза вследствие того, что было предсказано в исходном или в крайнем левом значении. Синяя область обозначает интервал доверия. «Goal Scored» мы видим, что забитый гол увеличивает вероятность получения награды ‘Лучший игрок’, но через некоторое время происходит насыщение.
Библиотека SHAP
SHAP (SHapley Additive explanation) - метод помогает разбить на части прогноз, чтобы выявить значение каждого признака. Он основан на Векторе Шепли, принципе, используемом в теории игр для определения, насколько каждый игрок при совместной игре способствует ее успешному исходу (https://medium.com/civis-analytics/demystifying-black-box-models-with-shap-value-analysis-3e20b536fc80).
SHAP – значения показывают, насколько данный конкретный признак изменил предсказание по сравнению при базовом значении этого признака. Допустим, мы хотели узнать, каким был бы прогноз, если бы команда забила 3 гола, вместо фиксированного базового количества.
Признаки, продвигающие прогноз выше, показаны красным цветом, а те, что понижают его точность – ниже.

Агрегирование множества SHAP-значений поможет сформировать более детальное представление о модели. Чтобы получить представление о том, какие признаки наиболее важны для модели, мы можем построить SHAP – значения для каждого признака и для каждой выборки. Сводный график показывает, какие признаки являются наиболее важными, а также их диапазон влияния на датасет.
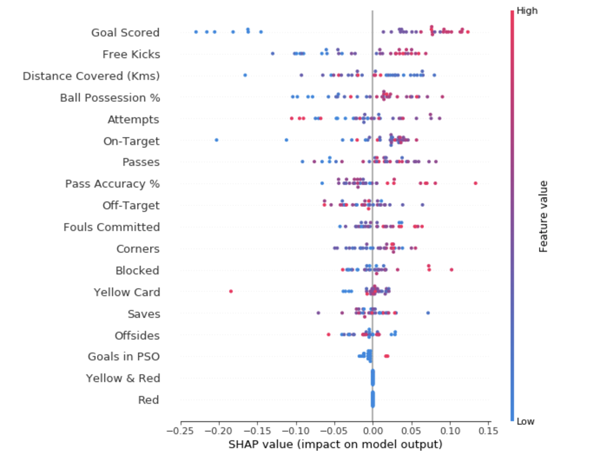
Для каждой точки цвет показывает, является ли этот объект сильно значимым или слабо значимым для этой строки датасета; Горизонтальное расположение показывает, привело ли влияние значения этого признака к более точному прогнозу или нет.
Значения упорядочены сверху вниз, вверху являются наиболее важными признаками, а значения в направлении к низу имеют наименьшее значение.
Первое число в каждой строке показывает, насколько снизилась производительность модели при случайной перетасовке (в данном случае с использованием "точности" в качестве метрики производительности). Существует некоторая случайность в точном изменении производительности от перетасовки столбца. Мы измеряем количество случайности в нашем вычислении важности перестановки, повторяя процесс с несколькими перестановками. Число после ± измеряет изменение производительности от одной перестановки к следующей. Иногда отображаются отрицательные значения импорта перестановок. В этих случаях прогнозы по перетасованным (или шумным) данным оказались более точными, чем реальные данные. Это происходит, когда функция не имела значения (должна была иметь значение, близкое к 0), но случайный шанс привел к тому, что прогнозы по перетасованным данным были более точными. Это чаще встречается с небольшими наборами данных, как в этом примере, потому что есть больше места для удачи/шанса. Некоторые веса отрицательны. Это связано с тем, что в этих случаях прогнозы по перетасованным данным оказались более точными, чем реальные данные.
Библиотека Yellowbrick
Yellowbrick https://www.scikit-yb.org/en/latest/ предназначена для визуализии признаков и расширяет Scikit-Learn API, чтобы упростить выбор модели и настройку гиперпараметров. Под капотом использует Matplotlib.
Библиотека LIME
LIME (локально интерпретируемое объяснение, не зависящее от устройства модели) - это библиотека Python, которая пытается найти интерпретируемую модель, предоставляя точные локальные объяснения https://github.com/marcotcr/lime.
Lime поддерживает объяснения для индивидуальных прогнозов широкого круга классификаторов. Встроена поддержка scikit-learn.
Ниже приведен пример одного такого объяснения проблемы классификации текста.
Вывод LIME представляет собой список объяснений, отражающих вклад каждой функции в прогноз выборки данных. Это обеспечивает локальную интерпретируемость, а также позволяет определить, какие изменения характеристик окажут наибольшее влияние на прогноз.

Библиотека MXLtend
Библиотека MLxtend содержит ряд вспомогательных функций для машинного обучения. Например, для StackingClassifier и VotingClassifier, эволюции модели, извлечения признаков, для разработки и для визуализации данных. С помощью MLxtend и сравним границы решения VotingClassifier и входящих в его состав классификаторов:
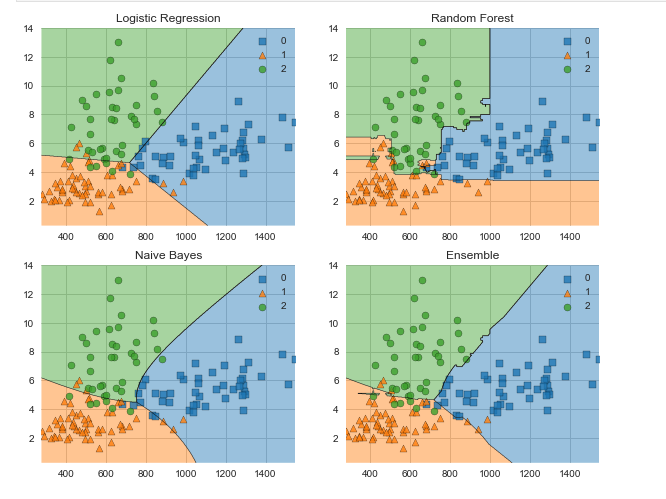
Заключение
Интерпретируемость модели важна не меньше, чем качество модели. Для того, чтобы добиться признания, крайне важно, чтобы системы машинного обучения могли предоставить понятные объяснения своих решений. Приведены основные библиотеки под Python для интерпретации модели, которые используют специалисты компании "К-Скай" при создании предиктивных моделей и управления рисками в здравоохранении.
Использованы источники:
- Rebecca Vickery. Python Libraries for Interpretable Machine Learning https://towardsdatascience.com/python-libraries-for-interpretable-machine-learning-c476a08ed2c7
- «Interpretable Machine Learning: A Guide for Making Black Box Models Explainable» Christoph Molnar
- Курс Machine Learning Explainability Micro Course на Kaggle
- OTUS. Онлайн-образование. Интерпретируемая модель машинного обучения. Часть 2 https://habr.com/en/company/otus/blog/465329/.